
Episode 3: Redshift Serverless Streaming Ingestion
Introduction
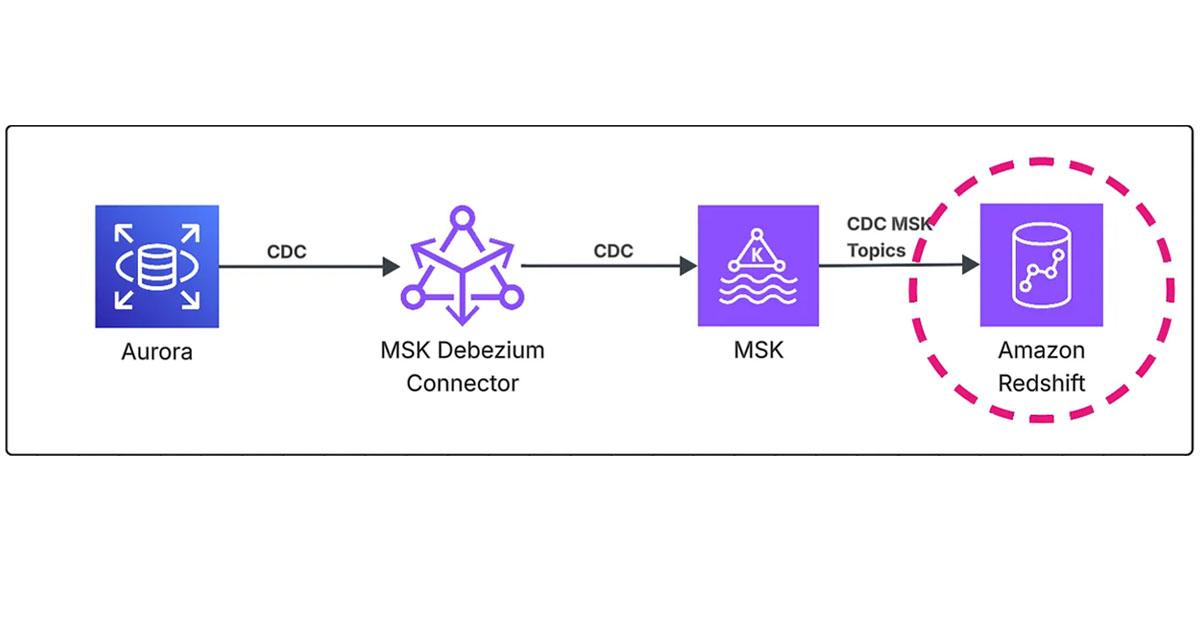
In the previous episodes, I covered the overall architecture design for this project and Debezium connector configuration for our CDC streaming pipeline. Now I’ll complete the series by diving deep into Amazon Redshift Serverless streaming ingestion — the final piece that enables real-time analytics on your CDC data.
This episode focuses on the practical implementation: setting up Redshift streaming ingestion from MSK topics, creating materialized views for real-time data access, and implementing stored procedures to process CDC events into target tables for analytics.
In This Episode, I’ll Cover
- External Schema Setup: Connecting Redshift to MSK topics with IAM authentication
- Materialized Views: Real-time data ingestion from Kafka topics
- CDC Data Processing: Stored procedures for handling INSERT, UPDATE, and DELETE operations
- Table Design: Optimized staging and target tables with proper encoding and distribution
- Scheduled Processing: Automating CDC data processing with scheduled queries
- Performance Optimization: Best practices for streaming ingestion and query performance
Prerequisites: Infrastructure Setup
Before configuring Redshift streaming ingestion, ensure you have completed the setup from previous episodes:
- Episode 1: Designing the End-to-End CDC Architecture and IaC Setup
- Episode 2: Configuring Debezium Connector for Reliable CDC
The Redshift cluster must have:
- Network connectivity to the MSK cluster (VPC, security groups, route tables)
- IAM role with MSK access permissions
- Enhanced VPC routing enabled for MSK connectivity
External Schema Configuration
The first step in setting up Redshift streaming ingestion is creating an external schema that connects Redshift to your MSK cluster. This schema acts as a bridge between Redshift and Kafka topics.
IAM Role Configuration
I configured a dedicated IAM role for Redshift streaming ingestion with the necessary MSK permissions:
resource "aws_iam_role" "redshift_streaming" {
name = "redshift-streaming-role"
assume_role_policy = data.aws_iam_policy_document.redshift_streaming_assume_role.json
}
data "aws_iam_policy_document" "redshift_streaming_policy_document" {
# MSK permissions for Redshift streaming ingestion
statement {
sid = "MSKIAMpolicy"
actions = [
"kafka-cluster:ReadData", # Read data from Kafka topics
"kafka-cluster:DescribeTopic", # Get topic metadata
"kafka-cluster:Connect", # Connect to MSK cluster
"kafka-cluster:DescribeCluster" # Get cluster information
]
resources = [
aws_msk_cluster.this.arn,
"arn:aws:kafka:${var.region}:${local.account_id}:topic/${aws_msk_cluster.this.cluster_name}/*"
]
}
# MSK cluster-level permissions
statement {
sid = "MSKPolicy"
actions = [
"kafka:GetBootstrapBrokers", # Get broker endpoints
"kafka:DescribeCluster" # Describe cluster details
]
resources = [aws_msk_cluster.this.arn]
}
# Redshift Serverless permissions for streaming ingestion
statement {
sid = "RedshiftServerlessStreaming"
actions = [
"redshift-serverless:GetCredentials" # Get temporary credentials
]
resources = [
"arn:aws:redshift-serverless:${var.region}:${local.account_id}:workgroup/${local.redshift_serverless_workgroup_name}"
]
}
}
Creating the External Schema
With the IAM role configured, I created the external schema in Redshift:
CREATE EXTERNAL SCHEMA analytics_platform_schema
FROM MSK
IAM_ROLE 'arn:aws:iam::YourAccountId:role/redshift-streaming-role'
AUTHENTICATION IAM
CLUSTER_ARN 'arn:aws:kafka:us-east-1:XXXXXXXXXXXX:cluster/streaming-pipeline-msk-cluster/your-cluster-uuid';
Key Configuration Parameters:
IAM_ROLE: The ARN of the IAM role with MSK access permissionsAUTHENTICATION IAM: Uses IAM authentication instead of username/passwordCLUSTER_ARN: The complete ARN of your MSK cluster, including the cluster UUID
Verifying External Tables
After creating the external schema, Redshift automatically creates external tables for each MSK topic. I verified the setup by querying the system view:
SELECT * FROM SVV_EXTERNAL_TABLES WHERE schemaname = 'analytics_platform_schema';
This query shows all external tables corresponding to your MSK topics. Information includes:
- Redshift Database Name
- Schema Name
- Table Name

For our CDC pipeline, we should see tables like:
analytics_platform.analytics_platform.customersanalytics_platform.analytics_platform.ordersanalytics_platform.analytics_platform.order_settings
The prefix analytics_platform.analytics_platform might differ in your case, based on how you configured Debezium and the topic prefix.
Important Note: Kafka topics can only be accessed through materialized views, not directly queried. Direct queries like SELECT * FROM myschema."topic_name" will fail.
Materialized Views for Real-Time Ingestion
Materialized views are the core component of Redshift streaming ingestion. They automatically refresh and provide real-time access to CDC data from MSK topics.
Creating Materialized Views
I created materialized views for each table we want to monitor for CDC changes:
CREATE MATERIALIZED VIEW mv_customers AUTO REFRESH YES AS
SELECT
*,
json_parse(kafka_value) as payload
FROM "dev"."analytics_platform_schema"."analytics_platform.analytics_platform.customers";
Key Features:
AUTO REFRESH YES: Automatically refreshes the view with new data from MSKjson_parse(kafka_value): Parses the JSON CDC event into a structured payload- Real-time Updates: New CDC events appear in the materialized view within seconds
Querying Materialized Views
Once created, you can query the materialized view to see CDC events:
SELECT * FROM "dev"."public"."mv_customers" ORDER BY refresh_time DESC;

The materialized view contains:
kafka_partition: Kafka partition informationkafka_offset: Message offset in the partitionkafka_timestamp_type: Type of timestamp (“C” for CREATE_TIME or “L” for LOG_APPEND_TIME)kafka_timestamp: When the message was produced to Kafkakafka_key: The Kafka message key (usually the primary key)kafka_value: The raw JSON CDC event from Debeziumkafka_headers: Additional metadata headers from Kafkarefresh_time: When Redshift last refreshed this rowpayload: Parsed JSON structure withbefore,after,source, andopfields
Manual Refresh (Optional)
While auto-refresh is enabled, you can manually refresh materialized views if needed:
REFRESH MATERIALIZED VIEW "dev"."public"."mv_customers";
Press enter or click to view image in full size

This is useful for:
- Testing and validation
- Ensuring immediate data availability
- Troubleshooting refresh issues
CDC Data Processing Architecture
Processing CDC events requires a sophisticated approach to handle INSERT, UPDATE, and DELETE operations correctly. I implemented a three-table architecture for reliable CDC processing.
Table Design Strategy
I designed three types of tables for CDC processing:
- Materialized Views: Real-time ingestion from MSK topics
- Staging Tables: Temporary processing tables for CDC events
- Target Tables: Final tables with the latest data state
Staging Table Design
Staging tables hold CDC events temporarily during processing:
CREATE TABLE public.customers_stg (
id INT ENCODE az64 DISTKEY,
first_name VARCHAR(100) ENCODE lzo,
last_name VARCHAR(100) ENCODE lzo,
email VARCHAR(255) ENCODE lzo,
phone VARCHAR(20) ENCODE bytedict,
address VARCHAR(255) ENCODE lzo,
city VARCHAR(100) ENCODE lzo,
state VARCHAR(50) ENCODE bytedict,
zip_code VARCHAR(10) ENCODE bytedict,
country VARCHAR(50) ENCODE bytedict,
registration_date TIMESTAMP ENCODE az64,
status VARCHAR(20) ENCODE bytedict,
ts_ms BIGINT ENCODE az64,
op VARCHAR(2) ENCODE bytedict,
record_rank SMALLINT ENCODE az64,
refresh_time TIMESTAMP WITHOUT TIME ZONE ENCODE az64
)
DISTSTYLE KEY
SORTKEY(id, refresh_time);
Optimization Features:
DISTKEY(id): Distributes data by primary key for efficient joinsSORTKEY(id, refresh_time): Sorts by primary key and refresh time for fast lookups and time-based queriesENCODE az64: High compression for numeric fields (id, registration_date, refresh_time)ENCODE lzo: Efficient compression for variable-length strings (names, email, address)ENCODE bytedict: Optimal for low-cardinality fields (phone, state, zip_code, country, status, operation types)
Target Table Design
Target tables store the final processed data:
CREATE TABLE public.customers_target (
id INT ENCODE az64 DISTKEY,
first_name VARCHAR(100) ENCODE lzo,
last_name VARCHAR(100) ENCODE lzo,
email VARCHAR(255) ENCODE lzo,
phone VARCHAR(20) ENCODE bytedict,
address VARCHAR(255) ENCODE lzo,
city VARCHAR(100) ENCODE lzo,
state VARCHAR(50) ENCODE bytedict,
zip_code VARCHAR(10) ENCODE bytedict,
country VARCHAR(50) ENCODE bytedict,
registration_date TIMESTAMP ENCODE az64,
status VARCHAR(20) ENCODE bytedict,
refresh_time TIMESTAMP WITHOUT TIME ZONE ENCODE az64
)
DISTSTYLE KEY
SORTKEY(id, refresh_time);
Key Differences from Staging:
- No CDC-specific fields (
ts_ms,op,record_rank) - Includes
refresh_timefor tracking when data was last updated - Optimized for analytical queries and reporting
Tracking Table for Incremental Processing
I created a tracking table to enable incremental CDC processing:
CREATE TABLE public.debezium_last_extract (
process_name VARCHAR(256) ENCODE lzo,
latest_refresh_time TIMESTAMP WITHOUT TIME ZONE ENCODE az64
) DISTSTYLE AUTO;
-- Insert initial tracking record
INSERT INTO public.debezium_last_extract VALUES ('customers', '1983-01-01 00:00:00');
This table tracks the last processed timestamp for each table, enabling incremental processing and avoiding reprocessing of historical data.
Stored Procedures for CDC Processing
The heart of CDC processing is the stored procedure that handles the complex logic of processing change events. I implemented a comprehensive stored procedure that handles all CDC operation types.
Core Stored Procedure Logic
CREATE OR REPLACE PROCEDURE public.incremental_sync_customers()
LANGUAGE plpgsql
AS $$
DECLARE
sql VARCHAR(MAX) := '';
max_refresh_time TIMESTAMP;
staged_record_count BIGINT := 0;
BEGIN
-- Get last loaded refresh_time from tracking table
sql := 'SELECT MAX(latest_refresh_time) FROM debezium_last_extract WHERE process_name = ''customers'';';
EXECUTE sql INTO max_refresh_time;
-- Truncate staging table
EXECUTE 'TRUNCATE customers_stg;';
-- Insert CDC records from mv_customers topic into staging table
EXECUTE '
INSERT INTO customers_stg
SELECT
COALESCE(payload.after."id", payload.before."id")::INT AS id,
payload.after."first_name"::VARCHAR,
payload.after."last_name"::VARCHAR,
payload.after."email"::VARCHAR,
payload.after."phone"::VARCHAR,
payload.after."address"::VARCHAR,
payload.after."city"::VARCHAR,
payload.after."state"::VARCHAR,
payload.after."zip_code"::VARCHAR,
payload.after."country"::VARCHAR,
DATEADD(second, payload.after."registration_date"::BIGINT / 1000, '1970-01-01 00:00:00'::TIMESTAMP),
payload.after."status"::VARCHAR,
payload.ts_ms::BIGINT,
payload."op"::VARCHAR,
RANK() OVER (
PARTITION BY COALESCE(payload.after."id", payload.before."id")::INT
ORDER BY payload.ts_ms DESC
) AS record_rank,
refresh_time
FROM mv_customers
WHERE refresh_time > ''' || max_refresh_time || ''';';
-- Count staged records
sql := 'SELECT COUNT(*) FROM customers_stg;';
EXECUTE sql INTO staged_record_count;
RAISE INFO 'Staged customer records: %', staged_record_count;
-- Delete matching records from target table
EXECUTE '
DELETE FROM customers_target
USING customers_stg
WHERE customers_target.id = customers_stg.id;';
-- Insert latest records (excluding deletes)
EXECUTE '
INSERT INTO customers_target
SELECT id, first_name, last_name, email, phone, address, city, state, zip_code, country, registration_date, status, refresh_time
FROM customers_stg
WHERE record_rank = 1 AND op <> ''d'';';
-- Record max refresh time
EXECUTE '
INSERT INTO debezium_last_extract
SELECT ''customers'', MAX(refresh_time)
FROM customers_target;';
END
$$;
Note on Date Field Conversion: CDC events deliver date/timestamp fields as epoch milliseconds (e.g., 1753279941000), which need to be converted to proper timestamps in Redshift. The DATEADD function converts these epoch milliseconds to readable timestamps by dividing by 1000 (to get seconds) and adding to the Unix epoch start date (1970-01-01 00:00:00).
Key Processing Logic
1. Incremental Processing:
- Retrieves the last processed timestamp from the tracking table
- Only processes CDC events newer than the last processed timestamp
- Enables efficient processing without reprocessing historical data
2. Change Event Handling:
- INSERT Operations:
payload.aftercontains the new record data - UPDATE Operations:
payload.beforecontains old data,payload.aftercontains new data - DELETE Operations:
payload.beforecontains the deleted record,payload.afteris null
3. Deduplication Logic:
- Uses
RANK()window function to identify the latest change for each record - Processes only
record_rank = 1(most recent) changes - Handles multiple updates to the same record correctly
4. Upsert Pattern:
- Deletes existing records from the target table
- Inserts the latest records (excluding deletes)
- Ensures the target table always contains the current state
5. Delete Handling:
- Filters out records where
op = 'd'(DELETE operations) - Ensures deleted records are removed from the target table
- Maintains data consistency with the source system
Challenges and Solutions
During implementation, I encountered several challenges specific to Redshift streaming ingestion and CDC processing that required specific solutions.
Challenge 1: Data Type Conversion Issues
Problem: Debezium sends some data types in formats that require conversion in Redshift.
Solution: Implemented proper data type casting in the stored procedure:
-- Handle decimal fields (already configured in Debezium as strings)
payload.after."price"::DECIMAL(10,2)
-- Handle timestamp fields (convert from epoch milliseconds)
DATEADD(second, payload.after."created_at"::BIGINT / 1000, '1970-01-01 00:00:00'::TIMESTAMP)
Challenge 2: Performance Optimization
Problem: Large volumes of CDC events can impact query performance.
Solution: Implemented several optimization strategies:
Table Design Optimizations:
- Proper distribution keys for even data distribution
- Sort keys for efficient query performance
- Column encoding for optimal compression
Query Optimizations:
- Incremental processing to minimize data volume
- Efficient window functions for deduplication
- Batch processing for better performance
Monitoring and Tuning:
- Regular VACUUM operations for high-change tables
- Monitor query performance and adjust as needed
Aurora and Redshift Optimization Recommendations
Both Aurora MySQL and Amazon Redshift provide optimization suggestions based on data querying patterns that are valuable for enhancing CDC pipeline performance:

Distribution Key Optimization:
- Aurora Insights: Provides recommendations for optimal distribution keys based on query patterns
- Redshift Advisor: Suggests distribution key changes based on join patterns and data access patterns
- Query Analysis: Both services analyze your workload to recommend:
- Even Distribution: Keys that distribute data evenly across nodes
- Join Optimization: Keys that minimize data movement during joins
- Query Performance: Keys that align with your most frequent query patterns
Key Considerations for CDC Pipelines:
- Primary Key Distribution: Use the primary key as the distribution key for even data distribution
- Time-Based Queries: Consider composite sort keys with timestamp fields for time-series analysis
- Join Patterns: Analyze how CDC data joins with other tables to optimize distribution
- Data Skew: Monitor for data skew that can impact performance
Implementation Strategy:
- Monitor Query Patterns: Use CloudWatch and Redshift system tables to identify common query patterns
- Analyze Join Frequency: Identify which tables are frequently joined together
- Review Distribution: Ensure data is evenly distributed across nodes
- Test Performance: Measure query performance before and after optimization changes
Automated Processing with Scheduled Queries
To ensure continuous CDC processing, I implemented automated execution using Redshift’s scheduled query feature.
Creating Scheduled Queries
I created scheduled queries that execute the stored procedures at regular intervals:
-- Create a simple query file for scheduling
CALL incremental_sync_customers();

Scheduling Configuration:
- Frequency: Every 1 minute for near real-time processing (minimum supported by Redshift)
- Error Handling: Automatic retry on failure
- Monitoring: Query execution history and performance metrics


Note on Frequency: Redshift scheduled queries support a minimum interval of 1 minute. For smaller intervals (e.g., seconds), consider using MSK event source mapping with Lambda functions to trigger stored procedures immediately when CDC events arrive, providing true real-time processing.
Conclusion
Redshift streaming ingestion completes our CDC pipeline by providing real-time access to change events for analytics. The combination of materialized views, stored procedures, and automated processing creates a robust foundation for real-time data analytics.
The key to success is understanding the CDC event structure, implementing proper data type handling, and optimizing for performance. The three-table architecture (materialized views, staging tables, target tables) provides flexibility and reliability for processing complex change events.
Next Steps
With the complete CDC pipeline now operational, you can:
- Extend to Additional Tables: Apply the same pattern to other tables in your source database
- Implement Data Quality Checks: Add validation logic to ensure data consistency
- Create Analytics Dashboards: Build real-time dashboards using the processed CDC data
- Monitor and Optimize: Continuously monitor performance and optimize as your data volume grows
Series Episodes
This article completes our comprehensive three-part series on implementing CDC streaming with Amazon Redshift, MSK, and Debezium:
Episode 1: Designing the End-to-End CDC Architecture Learn about the overall architecture design, infrastructure setup, and foundational components, including Aurora MySQL, Amazon MSK, Redshift Serverless, and network security configurations.
Episode 2: Configuring Debezium Connector for Reliable CDC Deep dive into Debezium configuration, data type challenges, deployment architecture, and production best practices.
Episode 3: Redshift Serverless Streaming Ingestion (Current Episode) Comprehensive coverage of Redshift Serverless streaming ingestion configuration, performance optimization, and real-time analytics implementation.
Author
Noor Sabahi | Senior AI & Cloud Engineer | AWS Ambassador
#CDC #DataStreaming #AmazonRedshift #MSK #Debezium #AWS #DataEngineering #StreamingIngestion #MaterializedViews #RealTimeAnalytics