
AWS Partner Revenue Measurement (PRM) Program

The Partner Revenue Measurement (PRM) program is an AWS initiative that measures service consumption driven by partner services and solutions. Quantifying the AWS consumption that partners generate across customer accounts has long been a challenge; PRM is AWS’s latest attempt to address this by providing automated, data-driven measurement across both partner and customer accounts. For partners, consumption […]
How I studied for and passed the AWS AI Practitioner (AIF-C01) Exam

Straight to the point. Why study for the AIF-C01 exam? This exam covers the AWS cloud, AWS services, and AWS artificial intelligence (AI) services, with growing emphasis on AWS security services. For aspiring and current data engineers or generative AI (genAI) developers, preparing for this exam will introduce AWS and its AI capabilities. The main benefits are […]
Agentic Readiness Analysis (ARA): The Step Most Teams Skip Before Building AI Agents

The Problem No One Talks About Everyone is building AI agents. Few are asking the right question first: Are my systems actually ready to be called by one? Many organizations build agents on top of systems that fundamentally don’t support them. The vulnerabilities were always there. Agents just amplify them at machine speed, and what was […]
Strands Multi-Agent Patterns: Which One Should You Use?
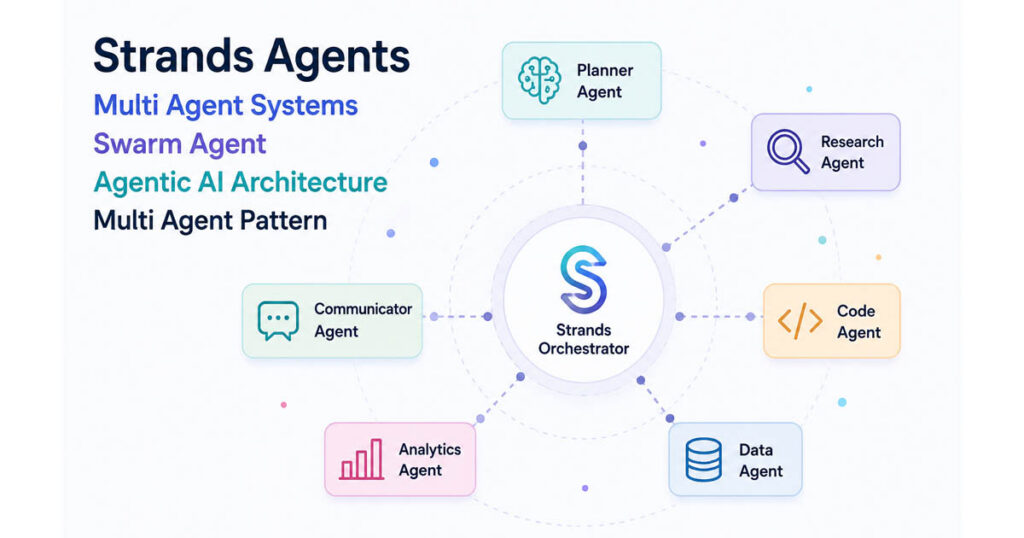
When I started building multi-agent systems with Strands Agents, the first decision I faced was architectural: which pattern fits my use case? Knowing what is available upfront saves you from reinventing the wheel — or worse, discovering mid-build that you picked the wrong structure. Strands offers five distinct patterns. Understanding each one lets you pick the […]
History-Aware Steering Files for Kiro-Enabled Repos

How to guide large-scale refactors and reorganizations using explicit, versioned rules instead of tribal memory Every repository tells a story. The problem is, most of that story is buried in commit logs, scattered Jira tickets, and the heads of two engineers who happen to remember why utils_v2_FINAL.py exists alongside utils_v3_backup.py. Over time, repos accumulate entropy. Modules overlap. Naming […]
AWS Agent Registry: A Complete Guide with Full Review
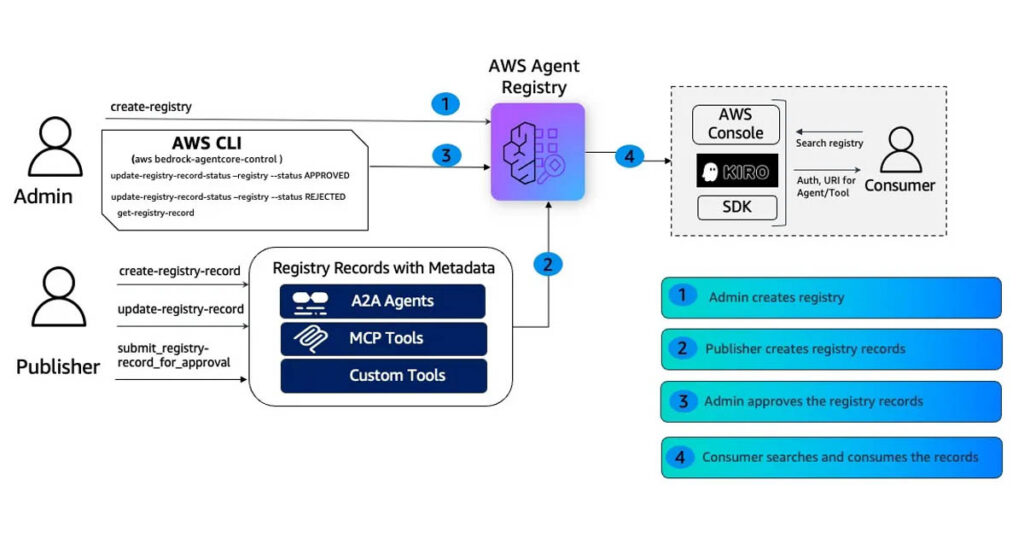
Introduction When I started building multi-agent systems on AgentCore, I quickly hit a problem that had nothing to do with the agents themselves: how do you control the visibility of deployed tools and MCP servers? Every target registered in AgentCore Gateway needed to be discoverable only when it was ready — but Gateway has no […]
Electrical Grid Fundamentals
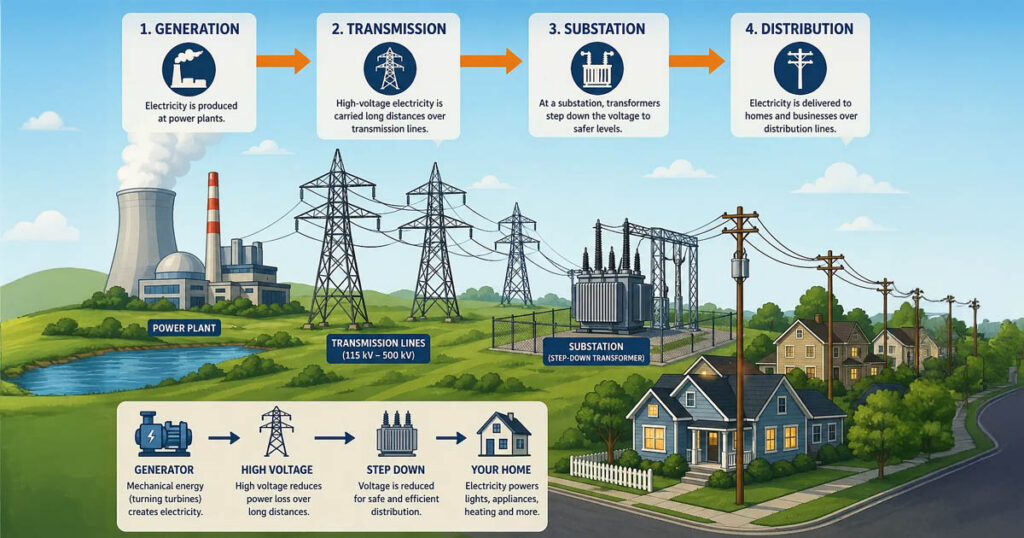
Yup, ChatGPT made this image with direction An ELI5 Explanation of Electricity and the Power Grid The electrical grid is an amazing system wherein power is used almost exactly when it is generated. I love learning more about it, and I am blessed to work with and lead some amazing teams in the electrical grid […]
The Roaming Terminal: Blink + mosh + Tailscale + tmux

It’s 2:07pm on a Tuesday. I’m deep in a codegen loop — Claude is running, files are being written, I’m watching diffs scroll and making small corrections, building momentum. Good session. My phone buzzes. Calendar notification: Dentist — cleaning. 2:30pm. I stare at it for a second. I don’t cancel the run. I don’t kill the […]
How to Pass the AWS DevOps Engineer Professional on the First Attempt — Exam Topics, Questions, and Study Plan

How to Pass the AWS DevOps Engineer Professional on the First Attempt — Exam Topics, Questions, and Study Plan In today’s article, I’ll share my experience on how to prepare for — and pass — the AWS Certified DevOps Engineer — Professional exam on the first attempt. I hope this helps anyone preparing for the exam […]
Scaling NL-to-SQL Agents with GraphRAG on AWS

Introduction This article addresses a specific problem in natural language to SQL generation: avoiding context overflow and LLM confusion when generating SQL queries against databases with a large number of tables and complex foreign key dependencies. The described solution uses GraphRAG to improve LLM accuracy by eliminating guesswork and reducing context pollution. The Problem Consider: an RDS PostgreSQL instance […]