
In the world of Big Data, choosing the right storage format is critical for the performance, scalability, and the efficiency of analytics and processing tasks. Apache Parquet, Apache ORC, and Apache Arrow are three popular formats commonly used for data storage and processing within the ecosystem. While each of these formats serves a distinct purposes and has unique optimizations, understanding their key features and best-use cases is essential to leveraging their full potential. This article explores the characteristics, strengths, and ideal use cases for these three formats of columnar data in the context of Big Data, with particular focus on their cloud integrations. When and how to use which columnar data stores is a topic we at New Math Data frequently come into contact with through our varied work in everything data.
Row-Based Storage vs. Columnar Storage
To fully appreciate the differences between Parquet, ORC, and Arrow, it is important to understand the distinction between row-based and columnar storage models.
Row-Based Storage
In row-based storage formats, data is stored row by row. This is the traditional format in relational databases, where each row represents a complete record. It is efficient for transactional systems (OLTP) where entire records are read or written together.

Each row is stored together, making it efficient for accessing or updating full records. However, when accessing only certain columns, unnecessary data is read, which can be inefficient.
Columnar Storage
Columnar storage formats like Parquet, ORC, and Arrow store data by columns rather than rows. This allows for efficient reading of specific columns without having to read the entire record.
Benefits of Columnar Storage:
- Efficient Analytical Queries: Columnar formats are highly efficient for analytical queries like SUM, AVG, COUNT, or filtering based on specific columns because, as only the required columns are accessed.
- Better Compression: Since data in a columnar format tends to be more homogeneous, it compresses better than row-based formats.
- Faster Aggregation: Aggregation operations are quicker because of the uniformity of data in each column.
Drawbacks of Columnar Storage:
- Not Ideal for OLTP: Columnar storage is not optimized for transactional workloads where entire rows are often read or written.
- Complex Data Retrieval for Full Records: Accessing complete records requires combining multiple columns, which can be slower than row-based formats in certain scenarios.
Why It Matters for Parquet, ORC, and Arrow
Parquet and ORC are both are columnar formats optimized for analytical workloads and are best suited for data warehousing and Big Data environments where query performance and storage efficiency are key. These formats excel in scenarios where only specific columns need to be accessed. Apache Arrow focuses on in-memory processing and data interchange. While it uses a columnar format like Parquet and ORC, its design is tailored for in-memory analytics and real-time data processing rather than long-term storage. It enables fast data exchange between systems, reducing serialization and deserialization overhead.
By understanding the benefits and trade-offs of each storage model and format, users can make the best choice based on their workload and performance requirements.
Apache Parquet

Overview:
Apache Parquet is a widely used columnar storage file format developed as part of the Apache Hadoop ecosystem. It is designed to efficiently handle large-scale data storage, retrieval, and processing. Parquet optimizes for query performance and storage efficiency, especially in data processing frameworks like Apache Spark, Hive, and Drill.
In addition to its robust ecosystem support, Apache Parquet is commonly used in cloud environments like Amazon Web Services (AWS), where it integrates seamlessly with services like Amazon S3 and AWS Athena. These integrations further enhance Parquet’s performance in large-scale analytics and cloud-native architectures.
Key Features:
- Columnar Storage: Parquet stores data in columns rather than rows, allowing for highly efficient compression and faster query performance, especially in analytical workloads.
- Schema Evolution: Parquet supports schema evolution, making it easier to add or modify columns over time without breaking existing data.
- Compression: Parquet includes support for various compression algorithms such as Snappy, Gzip, and LZO, ensuring reduced storage requirements.
- Cross-Platform Compatibility: Parquet is supported by a broad array of tools and frameworks, including Apache Spark, Apache Hive, Presto, and others.
Cloud Integration:
- Amazon S3 Compatibility: Parquet is often used in conjunction with Amazon S3, a scalable object storage service, to store large datasets in the cloud. Parquet’s columnar format and built-in compression reduce storage costs in S3 by significantly minimizing the data footprint.
- AWS Athena Integration: Parquet is natively supported by AWS Athena, a serverless interactive query service that allows you to run SQL queries directly on data stored in Amazon S3. Athena leverages the columnar nature of Parquet to enhance query performance by reading only the necessary columns, reducing I/O and speeding up query execution.
Best Use Cases:
- Large-scale data analytics: Parquet is well-suited for data warehousing and Big Data analytics on cloud platforms like AWS.
- Data warehousing: Its support for compression and efficient query performance make it ideal for cloud-based data lakes stored in Amazon S3.
- ETL pipelines: In cloud-native data pipelines, Parquet’s efficient compression and fast query capabilities ensure that the data processing and analytics workflow remains scalable and performant.
Pros:
- Efficient for large datasets due to its columnar storage format.
- Excellent query performance for analytical queries.
- High compression efficiency, making it ideal for use in cloud storage systems like Amazon S3.
- Seamless integration with AWS services like S3 and Athena for easy data access and querying.
Cons:
- Write performance may be slower for small-scale datasets or workloads with frequent updates.
- Limited performance for write-heavy workloads compared to row-based formats.
Apache ORC (Optimized Row Columnar)

Overview:
Apache ORC is another columnar storage format developed to optimize storage and query performance in large-scale data warehouses, particularly within the Hadoop ecosystem. ORC was designed to address performance issues faced by Hadoop-based systems and enhance query efficiency.
Add Your Heading Text Here
- Columnar Storage: Similar to Parquet, ORC also stores data in columns, improving read times and compression efficiency.
- Predicate Pushdown: ORC offers advanced predicate pushdown capabilities, allowing it to filter data during scanning, which enhances query performance.
- Lightweight Indexing: ORC files include lightweight indexing to speed up query processing, reducing the need for full table scans.
- Compression: ORC achieves excellent compression ratios through the use of lightweight compression algorithms like Zlib.
Best Use Cases:
- Complex queries in data warehousing environments.
- OLAP (Online Analytical Processing) systems.
- Hadoop-based workloads.
Cloud Integration:
- Amazon S3: ORC files are commonly stored in Amazon S3, benefiting from S3’s scalable storage solution. The columnar nature of ORC reduces storage costs due to efficient compression.
- AWS Athena and EMR: ORC is supported by AWS Athena for interactive querying, where it can perform well with large data volumes. Additionally, Amazon EMR (Elastic MapReduce) supports ORC in its Hadoop clusters, providing a powerful platform for distributed data processing and analysis.
Pros:
- Excellent query performance, particularly in Hadoop and Hive environments.
- Better compression efficiency compared to Parquet.
- Optimized for read-heavy workloads.
Cons:
Primarily optimized for Hadoop-based ecosystems, making it less widely supported outside of that environment.
Apache Arrow

Overview:
Apache Arrow is an in-memory columnar data format optimized for high-performance analytics. Unlike Parquet and ORC, Arrow is not intended for long-term storage. Instead, it focuses on in-memory data processing and data interchange between various systems, enabling faster operations and seamless integration across tools and frameworks.
Key Features:
- In-memory Format: Arrow is optimized for fast, in-memory analytics and supports zero-copy reads, enabling efficient sharing of data between systems.
- Cross-language Support: Arrow offers cross-language support for multiple programming languages, such as Python, R, C++, and Java, facilitating data exchange between different environments.
- Columnar Format: Similar to Parquet and ORC, Arrow uses a columnar format, but its focus is on high-speed in-memory operations rather than disk storage.
Cloud Integration:
- Cloud Data Lakes: Arrow is frequently used in cloud-native data processing environments like AWS Lambda, where it facilitates fast in-memory analytics in serverless computing. While Arrow does not handle persistent storage, it can be used as an intermediary format for efficient data interchange in cloud-based systems.
- AWS Glue & Athena: Though Arrow is not directly supported for querying, it can be used in AWS Glue jobs for high-performance data transformations, enabling seamless interaction with other data formats like Parquet and ORC.
Best Use Cases:
- Real-time analytics where in-memory processing is essential.
- Data science workflows requiring high-performance computation.
- Interchanging data between tools and systems (e.g., Python to Spark).
Pros:
- Highly optimized for in-memory analytics and real-time operations.
- Reduces serialization and deserialization overhead, improving data interchange efficiency.
- Ideal for low-latency, high-performance systems.
Cons:
- Not designed for long-term disk storage (i.e., no built-in compression or optimizations for storage).
- Limited ecosystem support for direct storage or querying compared to Parquet and ORC.
Comparing the Formats
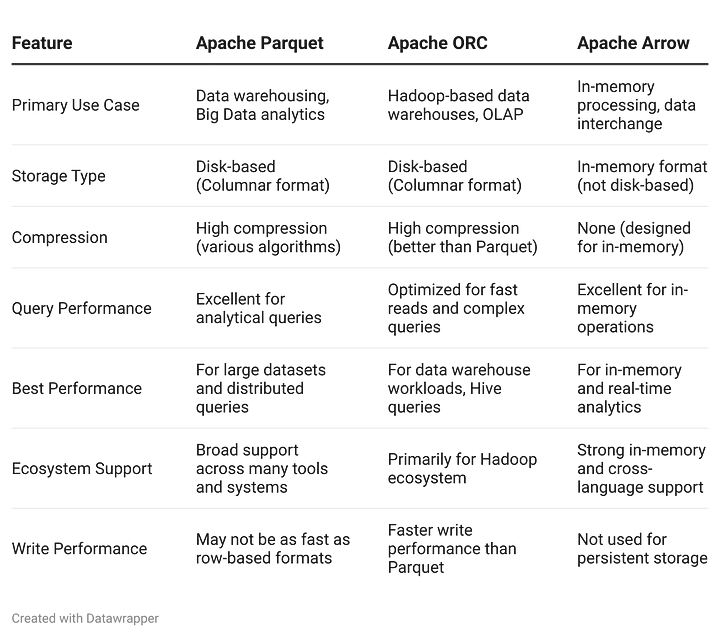
Choosing between Apache Parquet, ORC, and Arrow depends heavily on your specific use case. For cloud-native data lakes and serverless analytics, Parquet is an excellent choice due to its seamless easy integration with Amazon S3 and AWS Athena, making it ideal for large-scale, disk-based storage. ORC, on the other hand, is tailored for Hadoop ecosystems and optimized for read-heavy workloads in distributed environments. Finally, Arrow excels at in-memory analytics and real-time processing, making it ideal for low-latency systems and cross-platform data interchange. By evaluating the cloud capabilities and performance features of each format, you can ensure that your data pipeline is optimized for storage efficiency, query performance, and in-memory computation based on the unique requirements of your workload.
Thanks for reading! Please don’t hesitate to post your questions or comments, and we will get back to you.