
This series of blog posts will illustrate how to use DBT with Azure Databricks: set up a connection profile, work with python models, and copy noSQL data into Databricks(from MongoDB). In the second part, we will talk about working with python models.
Starting from version 1.3 python support is added to DBT.
As for now (Oct 2023) – only python models are supported (python can not be combined with Jinja for macros like SQL). Here I will share some basic things learned when implementing python models on DBT + Azure Databricks. Check part 1 for the DBT profile configuration.
According to the documentation: “A dbt Python model is a function that reads in dbt sources or other models, applies a series of transformations, and returns a transformed dataset.” So this python script contains a function that has to ALWAYS return a dataframe, otherwise, it will throw an error. The python script needs to be placed into DBT models directory or subdirectory within it.
DBT python models can be combined with SQL models, which is really nice! Python models can reference existing SQL models and vice versa:

By default, the result will be materialized as a table(in our case Delta table in Databricks with the same name as python script and located in the Catalog/Schema we provided in DBT profile, check part 1 for profile configuration).
If we need to perform an upsert(merge) operation into the existing table we can use settings materialized="incremental" and incremental_strategy="merge" and specify a unique column for merging. The Dataframe returned by the model will be upserted into the existing table with the same name.

To pass variables to python DBT model (for example environment or date), first, we need to specify them in dbt_project.yml (or config files in models/ directory) :

Then we need to specify key: value pairs for variables when calling dbt run(using the environment variable $ENVIRONMENT in this case)( if variable has a default value – it can be omitted):

And finally, inside the python model, we have access to the variable (it is important here to use a lowercase label – how we named this variable in the config file):

The default submission method for DBT python models on Databricks is all_purpose_cluster, it means that the Databricks cluster has to be created in advance and its id needs to be specified in the configuration.
Also, we can use an alternative submission method: job_cluster. It means that for every model, a new job cluster will be created with the given configuration and deleted once the model is done. The advantages of using job cluster: if some of the models need to be temporarily “empowered” – we can modify this config to another node type, increase/decrease the number of workers, and don’t worry about new clusters’ manual creation and deletion. On the other hand – it takes 3–5 minutes to start the new job cluster – and if we have multiple models running one after another – cluster creation will slow down the process significantly.
Additionally, the list of packages specified in +packages will be installed on the job cluster, and Databricks notebook will be generated automatically with +create_notebook: True option.

Entire models portion of dbt_project.yml:
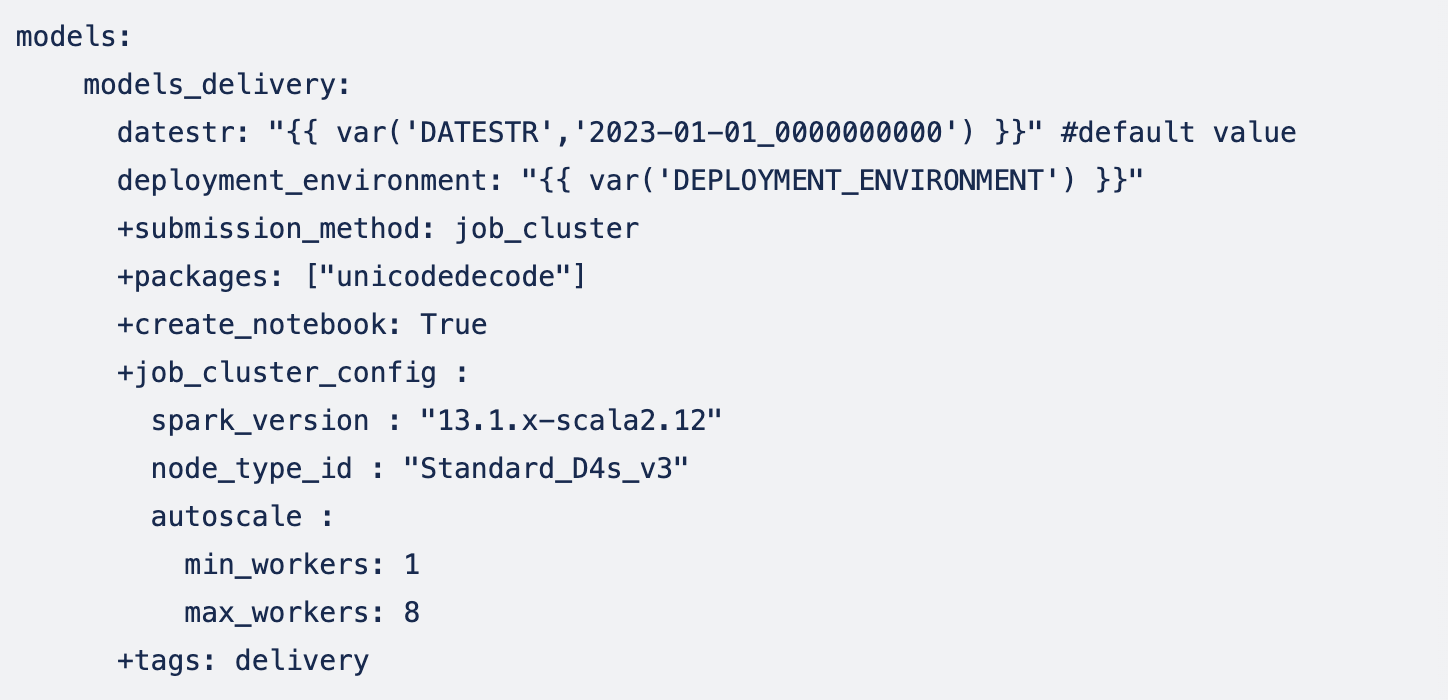
Then, we can start the models (this command will run all the models with delivery tag, from models/models_delivery directory):

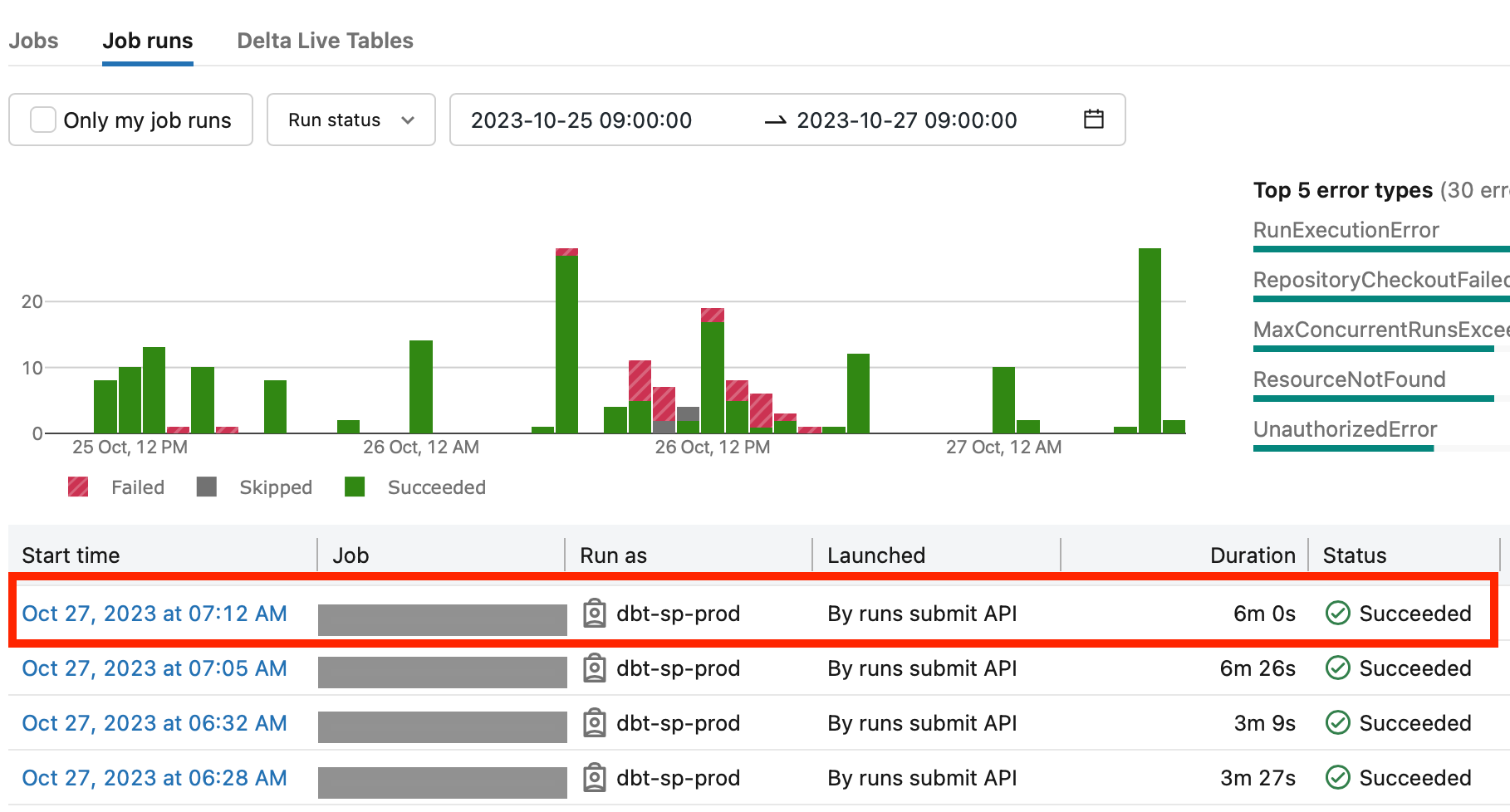
Now we can check the run status in Databricks UI → Workflows → Job runs:
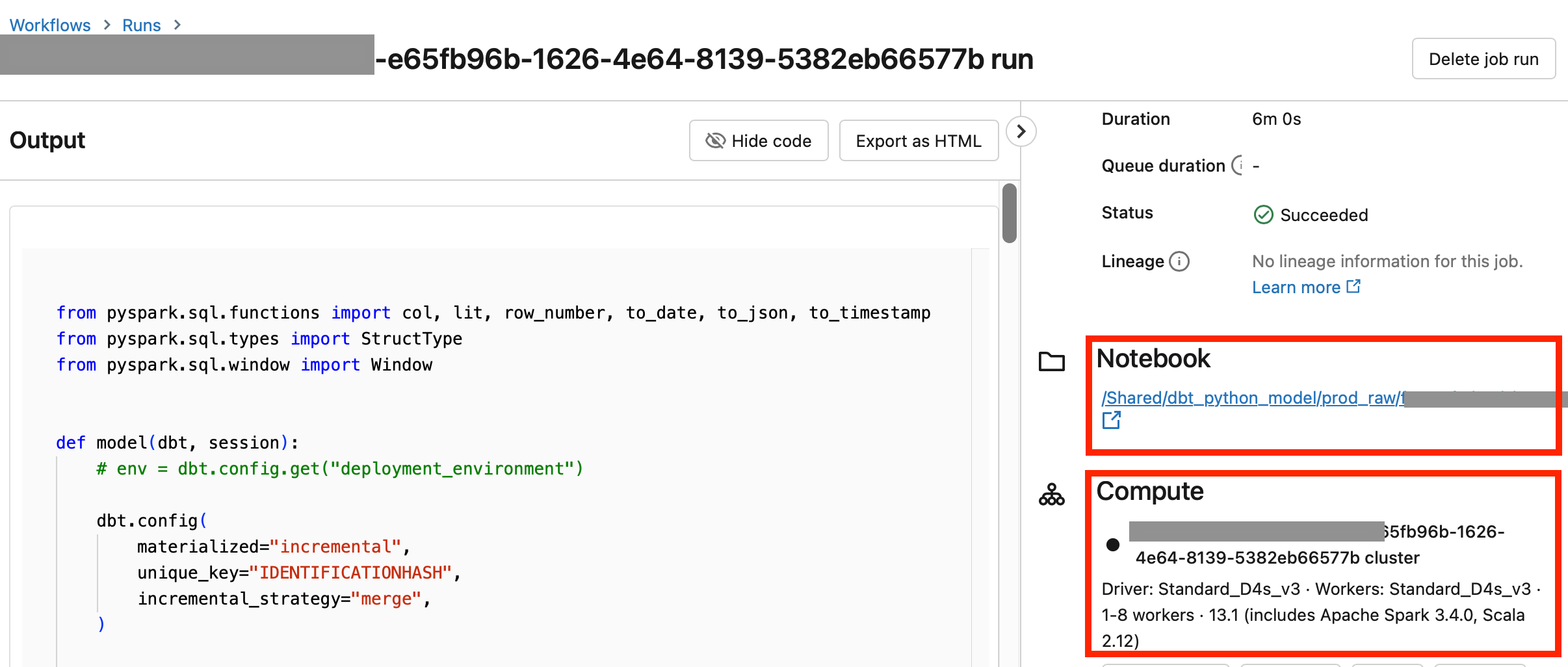
Clicking on individual run – it will show the generated notebook and job cluster configuration:
Summary:
- Databricks DBT python models are great for solving problems that are difficult to solve with SQL
- Databricks DBT python models are easy to integrate/add to existing SQL DBT code, and they have all the basic functionality, including the ability to upsert data.
Challenges:
- There is no
print()statement available(it’s not printing anywhere), so to be able to debug the model – we need to run the code manually in Databricks notebook, (create a new one or use the notebook that was created by default) and debug using this notebook. - There has yet to be any support for re-usable python functions across different models. For example – we have a separate python code for sending logs to ElasticSearch, to be able to use it – it should either be repeated in all the models or packaged in the python package and added to the DBT config as a package.