
Episode 1: Designing the End-to-End CDC Architecture and IaC Setup
Introduction
In today’s data-driven landscape, organizations need real-time insights from their operational databases to make informed decisions quickly. I developed a comprehensive Change Data Capture (CDC) streaming pipeline that captures database changes from Aurora MySQL and streams them in real-time to Amazon Redshift data warehouse for analytics.
This solution addresses the critical need for near real-time data synchronization between operational and analytical systems. Instead of traditional batch ETL processes that introduce latency, I implemented a streaming architecture that captures database changes as they occur and makes them immediately available for analytics.
This is the first episode in a three-part series that provides a technical explanation of how to set up end-to-end CDC from Aurora MySQL to Amazon Redshift using Debezium and MSK.
In this episode, I’ll cover the following points:
- Business Value and Use Cases
- Solution Architecture Overview
- Core Components
- Network Architecture and Security
- Data Flow and Processing
- IaC Setup and Multi-Environment Support
- Next Steps
Use Cases and Business Value
I designed this CDC streaming pipeline to solve several common enterprise challenges:
Real-time Analytics: Business teams can analyze customer behavior, sales trends, and operational metrics as events happen, enabling faster decision-making and competitive advantages.
Multiple Consumer Support: The MSK streaming pipeline can feed multiple downstream systems simultaneously, allowing different applications to consume the same change events for various purposes.
Compliance and Auditing: Every database change is captured and preserved, providing complete audit trails for regulatory compliance.
Operational Database Offloading: Streaming data to Redshift reduces analytical query load on Aurora, ensuring optimal transactional performance while enabling complex analytics on a dedicated system.
Solution Architecture Overview
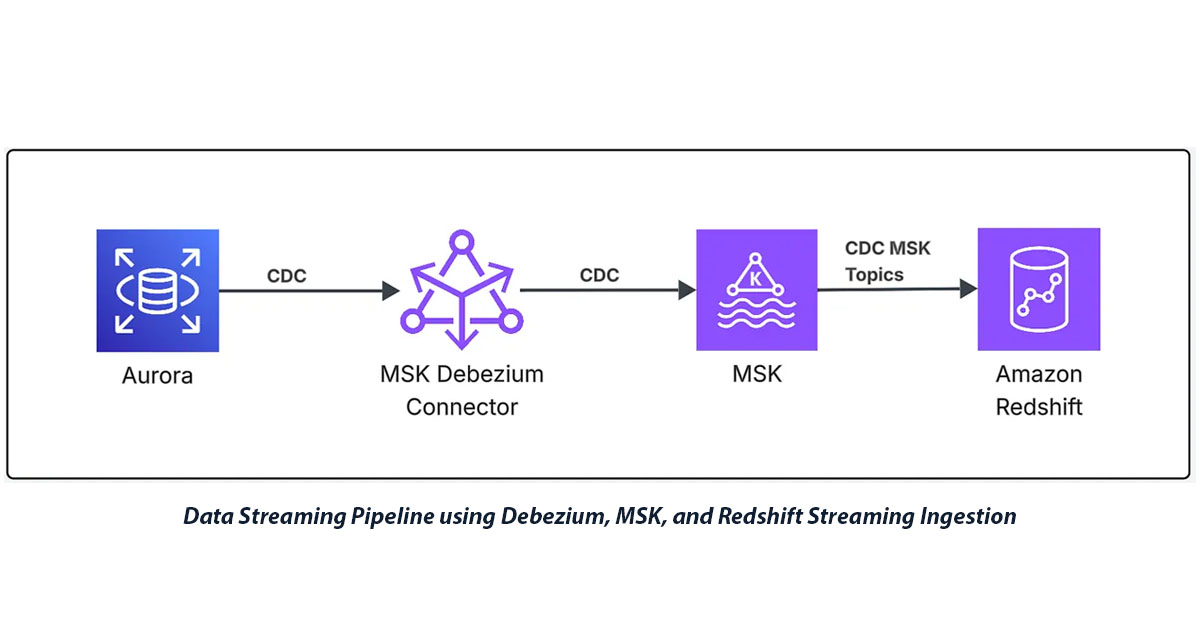
I architected an end-to-end streaming data pipeline using AWS managed services to ensure scalability, reliability, and minimal operational overhead. The solution captures changes from Aurora MySQL using Debezium connectors, streams them through Amazon MSK (Managed Streaming for Apache Kafka), and ingests them into Amazon Redshift for real-time analytics.

The architecture consists of four main components working together:
Core Components
Amazon Aurora MySQL Cluster serves as the source database for CDC operations:
- Function: Captures all data modifications in real-time through binary logging
- Security: Restricts connections to authorized resources on port 3306, with bastion host access for administration
- CDC Access: Debezium connects via a dedicated database user with limited permissions
- Monitoring: Database logs and Performance Insights track query performance and identify bottlenecks
# Enable binary logging for Aurora MySQL
resource "aws_rds_cluster_parameter_group" "aurora_binlog" {
name = "${var.aurora_cluster_name}-binlog-param-group"
family = "aurora-mysql8.0"
description = "Aurora MySQL parameter group with binlog enabled"
parameter {
name = "binlog_format"
value = "ROW"
apply_method = "pending-reboot"
}
parameter {
name = "binlog_row_image"
value = "FULL"
apply_method = "pending-reboot"
}
parameter {
name = "binlog_checksum"
value = "NONE"
apply_method = "pending-reboot"
}
}
Debezium Connector running on MSK Connect handles change data capture:
- Function: Parses Aurora binary logs and converts changes to JSON format
- Deployment: Custom plugin uploaded to S3 and deployed via MSK Connect
- Capabilities: Captures initial snapshots and ongoing changes for complete data consistency
- Output: Publishes structured events to Kafka topics
- Monitoring: CloudWatch logs provide connector status and error tracking for real-time CDC monitoring
Note: Episode 2 covers detailed Debezium configurations and setup challenges.
Amazon MSK (Managed Streaming for Apache Kafka) provides the streaming backbone:
- Function: Durable, scalable message queues that buffer change events for multiple consumers
- Security: TLS encryption in transit, IAM authentication, port 9098 access from authorized security groups only, which eliminates certificate and password management through AWS IAM integration. Port 9098 is used in MSK clusters to communicate with brokers when IAM (Identity and Access Management) access control is enabled for a cluster, and it is used to access within AWS. Use port 9198 for public access.
- Monitoring: CloudWatch metrics track message throughput, consumer lag, and cluster health
- Architecture: Multi-broker setup ensures fault tolerance and high availability
resource "aws_msk_cluster" "this" {
cluster_name = "streaming-pipeline-msk-cluster"
kafka_version = "3.9.x"
number_of_broker_nodes = 3
broker_node_group_info {
instance_type = "kafka.m5.large"
client_subnets = module.vpc.private_subnets
security_groups = [aws_security_group.msk_sg.id]
}
encryption_info {
encryption_in_transit {
client_broker = "TLS"
in_cluster = true
}
}
client_authentication {
sasl {
iam = true
}
}
}
Amazon Redshift Serverless provides real-time analytics capabilities:
- Function: Native streaming ingestion from MSK topics without additional ETL processes
- Security: Enhanced VPC routing, private subnet deployment, security group access control
- IAM: Minimal required permissions for MSK access and streaming ingestion
- Monitoring: Query performance and streaming ingestion metrics via CloudWatch
resource "aws_redshiftserverless_namespace" "this" {
namespace_name = "streaming-pipeline-redshift-namespace"
admin_username = jsondecode(aws_secretsmanager_secret_version.redshift_admin_credentials.secret_string)["username"]
admin_user_password = jsondecode(aws_secretsmanager_secret_version.redshift_admin_credentials.secret_string)["password"]
iam_roles = [aws_iam_role.redshift_streaming.arn]
log_exports = ["userlog", "connectionlog", "useractivitylog"]
}
resource "aws_redshiftserverless_workgroup" "this" {
workgroup_name = "streaming-pipeline-redshift-workgroup"
namespace_name = aws_redshiftserverless_namespace.this.namespace_name
base_capacity = 8
subnet_ids = module.vpc.private_subnets
security_group_ids = [aws_security_group.redshift_serverless_sg.id]
publicly_accessible = false
enhanced_vpc_routing = true # Critical for MSK connectivity
}
Note: For the purpose of learning in this workshop, I experimented with both Amazon Redshift Serverless and provisioned clusters. This series focuses on Redshift Serverless and the lessons learned.
IAM Policies for secure MSK access and streaming ingestion:
resource "aws_iam_role" "redshift_streaming" {
name = "redshift-streaming-role"
assume_role_policy = data.aws_iam_policy_document.redshift_streaming_assume_role.json
}
data "aws_iam_policy_document" "redshift_streaming_policy_document" {
# MSK permissions for Redshift streaming ingestion
statement {
sid = "MSKIAMpolicy"
actions = [
"kafka-cluster:ReadData", # Read data from Kafka topics
"kafka-cluster:DescribeTopic", # Get topic metadata
"kafka-cluster:Connect", # Connect to MSK cluster
"kafka-cluster:DescribeCluster" # Get cluster information
]
resources = [
aws_msk_cluster.this.arn,
"arn:aws:kafka:${var.region}:${local.account_id}:topic/${aws_msk_cluster.this.cluster_name}/*"
]
}
# MSK cluster-level permissions
statement {
sid = "MSKPolicy"
actions = [
"kafka:GetBootstrapBrokers", # Get broker endpoints
"kafka:DescribeCluster" # Describe cluster details
]
resources = [aws_msk_cluster.this.arn]
}
# Redshift Serverless permissions for streaming ingestion
statement {
sid = "RedshiftServerlessStreaming"
actions = [
"redshift-serverless:GetCredentials" # Get temporary credentials
]
resources = [
"arn:aws:redshift-serverless:${var.region}:${local.account_id}:workgroup/${local.redshift_serverless_workgroup_name}"
]
}
}
Note: Episode 3 covers detailed Redshift Serverless configuration, streaming ingestion setup, and performance optimization.
Network Architecture and Security
I designed a secure, multi-tier network architecture using Amazon VPC with nine subnets across three Availability Zones for high availability and fault tolerance.

- Three Public Subnets (one per AZ) provide internet connectivity and host NAT gateways for outbound traffic from private resources. These subnets also contain the bastion host for secure administrative access to private resources.
- Three Private Subnets (one per AZ) house the core streaming infrastructure, including MSK brokers and MSK Connect workers. This placement ensures these critical components are not directly accessible from the internet while maintaining outbound connectivity through NAT gateways.
- Three Database Subnets (one per AZ) provide the most secure tier for Aurora MySQL, completely isolated from direct internet access and accessible only through carefully controlled security group rules from within the VPC.
Data Flow and Processing
The data flows through the pipeline in the following sequence:
- Change Capture: Aurora MySQL generates binary logs for all data modifications (INSERT, UPDATE, and DELETE operations).
- Stream Processing: Debezium connector reads the binary logs and converts changes to JSON format, publishing them to MSK topics with the naming pattern
{topic.prefix}.{database}.{table}. - Message Queuing: MSK stores the change events durably across multiple brokers, providing fault tolerance and enabling multiple consumers.
- Real-time Ingestion: Redshift Serverless continuously consumes from MSK topics using streaming ingestion, automatically creating and updating tables based on the incoming data structure.

Infrastructure as Code Implementation
I implemented the entire infrastructure using Terraform, ensuring reproducible deployments and infrastructure versioning. The modular approach allows for easy customization and scaling based on specific requirements.
Multi-Environment Support
The Terraform implementation supports multiple environments (dev, prod, and uat) through a flexible configuration approach that can be easily extended to support additional environments. Each environment maintains its own state and variable configurations while sharing the same infrastructure code base.
The multi-environment setup uses Terraform workspaces combined with environment-specific configuration files. Adding a new environment requires only two files: a backend configuration file and a variables file. This approach ensures consistency across environments while allowing for environment-specific customizations.
terraform/
├── main.tf # Core infrastructure definitions
├── variables.tf # Variable declarations
├── outputs.tf # Output definitions
├── versions.tf # Provider and version constraints
...
├── env/ # Environment-specific configurations
│ ├── dev/
│ │ ├── backend.conf # S3 backend configuration for dev
│ │ └── terraform.tfvars # Dev environment variables
│ ├── prod/
│ │ ├── backend.conf # S3 backend configuration for prod
│ │ └── terraform.tfvars # Prod environment variables
│ ├── uat/
│ │ ├── backend.conf # S3 backend configuration for uat
│ │ └── terraform.tfvars # UAT environment
...
Each environment’s backend.conf file specifies the S3 bucket and key path for storing the Terraform state:
# env/prod/backend.conf
bucket = terraform-state-bucket-names"
key = "key-to-state-file/prod/terraform.tfstate"
region = "us-east-1"
use_lockfile = true
encrypt = true
I am using Terraform’s new S3-native state locking feature (use_lockfile = true), which stores a .tflock file in the same S3 bucket as the state file instead of using DynamoDB.
The terraform.tfvars files contain environment-specific values:
# env/prod/terraform.tfvars
environment = "prod"
region = "us-east-1"
# Aurora configuration
...
Deployment to any environment is simplified through the deployment script:
# Init development
terraform init -backend-config=env/dev/backend.config
# Deploy to development
terraform apply -var-file=env/dev/terraform.tfvars
# Init production
terraform init -backend-config=env/prod/backend.config
# Deploy to production
terraform apply -var-file=env/prod/terraform.tfvars
This multi-environment approach provides several key benefits:
- Environment Isolation: Each environment maintains separate state files and resources
- Consistent Infrastructure: All environments use the same Terraform code, ensuring consistency
- Easy Scaling: Adding new environments requires minimal configuration
- Environment-Specific Sizing: Each environment can have different resource sizes based on requirements
- Automated Deployments: Scripts handle the complexity of environment-specific deployments
Automated Resource Tagging
I implemented Terraform’s default tags feature at the provider level to ensure consistent tagging across all AWS resources without manually adding tags to each resource. This approach significantly reduces code duplication and ensures compliance with organizational tagging policies.
provider "aws" {
region = var.region
default_tags {
tags = {
Project = "data_streaming_pipeline"
Owners = "Noor"
Provisioner = "Terraform"
}
}
}
Resources can still have additional specific tags when needed, and the default tags are merged with resource-specific tags. This approach ensures that critical metadata like project ownership, provisioning method, and environment information is consistently applied across the entire infrastructure.
Conclusion
This CDC streaming architecture provides a robust foundation for real-time data processing using AWS managed services. The infrastructure-as-code approach ensures consistent deployments, while the security-first design protects sensitive data throughout the pipeline.
The modular design allows for easy scaling and customization based on specific requirements. By leveraging managed services, I minimized operational overhead while maintaining high availability and performance.
Next Steps
This article is part of a comprehensive three-part series on implementing CDC streaming with Amazon Redshift, MSK, and Debezium:
Episode 1: Designing the End-to-End CDC Architecture (Current Episode) Learn about the overall architecture design, infrastructure setup, and foundational components, including Aurora MySQL, Amazon MSK, Redshift Serverless, and network security configurations.
Episode 2: Configuring Debezium Connector for Reliable CDC (Coming Soon) Deep dive into Debezium configuration, data type challenges, deployment architecture, and production best practices.
Episode 3: Redshift Serverless Streaming Ingestion (Coming Soon) Comprehensive coverage of Redshift Serverless streaming ingestion configuration, performance optimization, and real-time analytics implementation.
Author
Noor Sabahi | Senior AI & Cloud Engineer | AWS Ambassador
#CDC #DataStreaming #AmazonRedshift #MSK #Debezium #AWS #DataEngineering #DebeziumPlugin #Aurora #IaC #Kafka