
A super colorful infographic ChatGPT created for this article.
How linguistic fundamentals shape the design and performance of retrieval-augmented generation systems
In a previous article, I discussed the core concepts of computational linguistics that every language model, big and small, needs to have. This article will discuss the core components of retrieval-augmented generation (RAG) models, show how the concepts of computational linguistics are related to RAG, and illustrate how we might use those core concepts to successfully build and optimize RAG models.
The computational linguistics concepts mentioned in the previous article that I will discuss within the context of RAG are tokenization, morphological analysis, syntactic analysis, semantic analysis, pragmatic analysis, and natural language generation.
What is Retrieval-Augmented Generation?
RAG is a hybrid architecture that combines a retriever with a generator to enhance the factual accuracy of an LLM and reduce hallucinations. The process can be broken into four main stages:
- Query Encoding: A user input or prompt is encoded into a query vector.
- Document Retrieval: Relevant documents are fetched from an external corpus using similarity search. This is usually a dense vector search that is performed over a knowledge base.
- Augmentation: Retrieved documents are fed back into the prompt to have a more accurate and informative input for the LLM.
- Contextual Generation: Retrieved content is passed to a generator model or LLM (e.g., a transformer-based decoder), which produces a fluent and contextually relevant output.
Originally introduced by Lewis et al. in their 2020 seminal paper, “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, RAG combines the benefits of information retrieval with the flexibility of neural text generation. Neural language models use neural networks to both understand and produce natural language.
RAG Flow

1. User Input:
The raw natural language input provided by the user. This is typically a question, prompt, or instruction. Sometimes we derive the input from a pipeline, and sometimes there’s a direct user interface.
2. Tokenization and Parsing:
Tokenization splits the input text into discrete units or tokens that the models can understand, such as words or subwords. Parsing is an optional step that applies syntactic analysis, effectively creating a dependency tree or sentence diagram under the hood, to help models understand grammatical structure and resolve ambiguities in meaning. This prepares the input for meaningful embedding and improves retriever relevance through better query understanding.
Dependency parsing might be especially useful if you are working on a RAG model for a very specialized use case or when the user is using complex sentence structure. Let’s take the following sentence: “Subject to prior written consent by the disclosing party, the receiving party shall not disclose Confidential Information to any third party, except as required by applicable law.” The dependency tree appears as below:
ROOT: disclose
├── aux: shall
├── neg: not
├── nsubj: party
│ └── amod: receiving
├── dobj: Information
│ └── amod: Confidential
├── prep: to
│ └── pobj: party
│ └── amod: third
├── advcl: subject
│ └── pobj: consent
│ └── amod: written
│ └── agent: party
│ └── amod: disclosing
└── advcl: except
└── prep: by
└── pobj: law
└── amod: applicable
In this example, without the parser, your retriever may not get the memo that disclosure might happen without prior consent, or it may fail to understand who gives consent vs. who receives consent.
Using a parser like spaCy or CoreNLP may meet your needs. Still, a custom parser step may be necessary in super specialized legal, financial, or particular scientific domains to pass information correctly to the embedder or retrieve the most relevant data through the retriever. Nonstandard grammar, long noun phrases, and context-dependent modifiers can be tricky for the common parsers to break down appropriately.
3. Embedding:
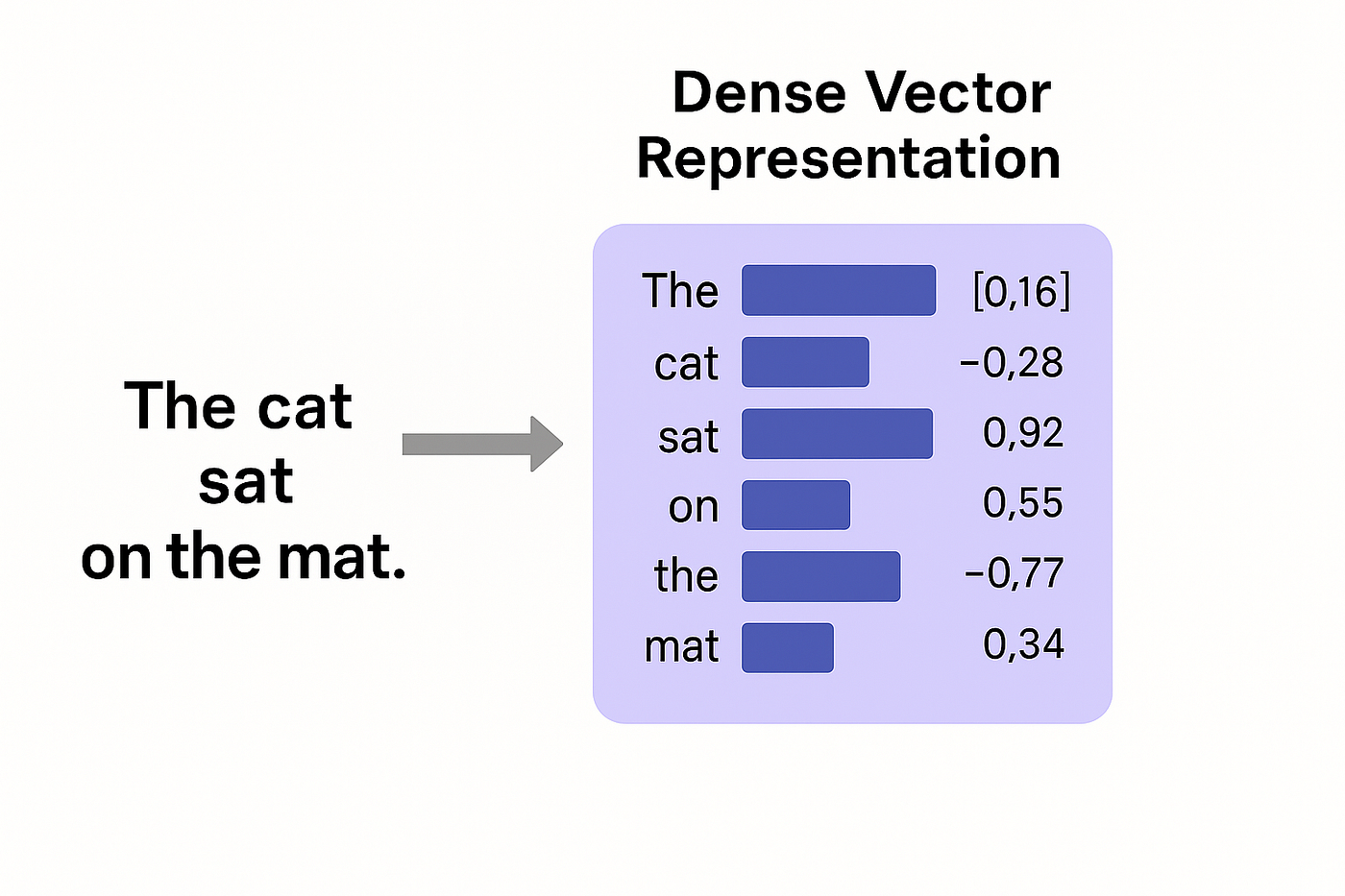
Transforms the tokenized query into a dense vector representation or embedding that performs semantic analysis to derive meaning. Sentence-BERT, Dense Passage Retriever (DPR) encoder, and other transformer-based embedding models can be used here.
At the risk of being overly general and missing the nuance in specific embedding models, dense vector representations provide decimal values within the vector instead of 1s and 0s, as is the case in sparse vectors. Dense vectors allow for semantic meaning to be passed through the decimals via various underlying algorithms by representing similarities between words and concepts in the text. For example, the vector will represent that the words “art” and “painting” are semantically related.
Word2Vec, GloVe, and BERT models are context-aware and attempt to perform some pragmatic analysis to determine hidden or nuanced meanings, though this is a constantly evolving part of RAG development. For example, these models can understand the difference between “he shot the photo” and “he shot the gun”. Even though both use the word “shot”, the context is very different between the two uses.
4. Retrieval:
Uses the query embedding to search a pre-encoded corpus and perform semantic analysis to return the most relevant documents. Retrieval typically uses FAISS or other vector search libraries and retrieves the top k documents. Here, retrieval is similarity-based, not keyword-based. Interestingly, the seminal Lewis et al. paper on RAG mentioned above did not find significant differences in the performance of retrieving 5 or 10 documents.
A ranked list of documents or passages deemed most relevant to the query is pulled from a vectorized knowledge base, and the top k are picked from that list. The content could be product manuals, web pages, PDFs, legal documents, support articles, etc.
While similarity-based retrieval is the most common, based on your use case, it may make sense to create a custom retriever to pull out keywords from the previous steps and pass them to a more generic API. You might do this if there is a good keyword API out there for your project, or if trying to reduce computation costs.
5. Generator:
A decoder-only or encoder-decoder model (like BART, T5, or GPT) that takes the query and retrieved documents as input and generates a fluent, context-aware response using natural language generation. The actual generation is the easy part. Everything that came before ensures the response is contextually accurate and without hallucinations.

Natural language generation uses cross-attention to blend the query and retrieved context, is often fine-tuned for specific downstream tasks, and can handle paraphrasing, summarizing, or answering questions about the response. Cross-attention is a core concept in neural networks, specifically transformer models with encoder-decoder architectures, where a RAG model could focus on the retrieved documents. Without cross-attention, hallucinations would be much more prevalent because the decoder would not have the additional external context.
Although perhaps unclear in the image above, the queries typically come from the decoder, and the keys and values typically come from the encoder. The decoder is repeatedly trying to summarize what it knows, using the output of the encoder to reference what it is trying to write and keep it factually honest. This process will occur iteratively until the final result is produced.
6. Result:
The final text output, grounded in the retrieved knowledge and refined by the generator’s language modeling capabilities, is produced using all 5 of the previous steps.
Why Linguistics Still Matters in LLM Architectures
Despite the emergence of end-to-end architectures, computational linguistics remains essential in building effective RAG systems. Understanding how language is structured, interpreted, and used in context allows engineers to design systems that not only perform well on benchmarks but also meet the nuanced needs of users in real-world applications.
By integrating core linguistic insights into retrieval strategies, document processing, and output generation, we can continue to push the boundaries of what RAG models can achieve. At New Math Data, we have deep expertise in data and AI systems, where RAG is just one of many tools in our toolbox. Please reach out or comment below to share your experiences with or ideas about computational linguistics or RAG!