
Episode 2: Configuring Debezium Connector for Reliable CDC
Introduction
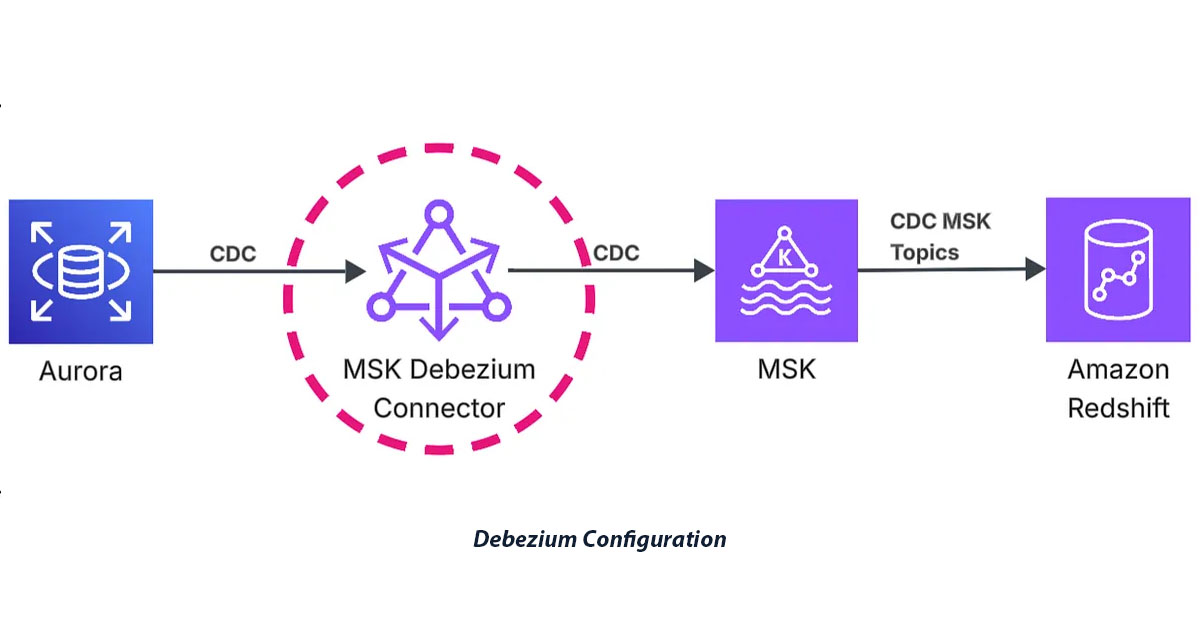
In the previous episode, I covered the overall architecture and infrastructure setup for our CDC streaming pipeline. Now I’ll dive deep into Debezium — the open-source platform that captures row-level database changes in real-time and streams them to Kafka topics through MSK Connect.
This episode focuses on the practical implementation, including configuring Debezium connectors, resolving real-world data type challenges, and deploying a production-ready CDC solution.
In This Episode, I’ll Cover
- MSK Prerequisites: Essential cluster configuration for topic auto-creation
- Debezium Configuration: Complete connector setup with key parameters
- Debezium Message Structure: Understanding Debezium’s JSON event format
- Debezium Data Type Challenges: Solving decimal and datetime field issues
- Deployment Architecture: MSK Connect setup with custom plugins and scaling
- Configuration Management: Handling deployment challenges and solutions
Prerequisites: MSK Cluster Configuration
Before configuring Debezium, you must first set up MSK to allow automatic topic creation. By default, MSK doesn’t allow connectors to create topics automatically, which Debezium requires for its internal topics (schema history, offsets, etc.).
resource "aws_msk_configuration" "msk_config_auto_create_topics" {
name = "auto-create-topics-config"
kafka_versions = [var.msk_kafka_version]
server_properties = <<PROPERTIES
auto.create.topics.enable = true
delete.topic.enable = true
PROPERTIES
}
resource "aws_msk_cluster" "this" {
cluster_name = "streaming-pipeline-msk-cluster"
kafka_version = var.msk_kafka_version
number_of_broker_nodes = var.msk_broker_count
broker_node_group_info {
instance_type = var.msk_broker_instance_type
client_subnets = module.vpc.private_subnets
security_groups = [aws_security_group.msk_sg.id]
}
encryption_info {
encryption_in_transit {
client_broker = "TLS"
in_cluster = true
}
}
client_authentication {
sasl {
iam = true
}
}
configuration_info {
arn = aws_msk_configuration.msk_config_auto_create_topics.arn
revision = aws_msk_configuration.msk_config_auto_create_topics.latest_revision
}
}
Key Configuration Properties:
auto.create.topics.enable = true: Allows Debezium to automatically create required topics for schema history and offsetsdelete.topic.enable = true: Enables topic deletion for cleanup operations during development
Without this configuration, the Debezium connector deployment won’t be able to create topics.
Debezium Connector Configuration
Debezium provides a comprehensive set of configuration options for MySQL connectors. Let me walk through the key configurations I implemented and explain their purpose.
Core Connector Configuration
I deployed Debezium using MSK Connect, which provides a managed environment for running Kafka Connect connectors. Here’s the complete configuration:
resource "aws_mskconnect_connector" "debezium_mysql" {
name = "debezium-mysql-connector"
kafkaconnect_version = "3.7.x"
connector_configuration = {
# Core connector settings
"connector.class" = "io.debezium.connector.mysql.MySqlConnector"
"tasks.max" = "1"
"include.schema.changes" = "true"
"topic.prefix" = "YOUR-TOPIC-PREFIX"
# Data format configuration
"value.converter" = "org.apache.kafka.connect.json.JsonConverter"
"key.converter" = "org.apache.kafka.connect.storage.StringConverter"
"decimal.handling.mode" = "string"
# Database connection settings
"database.user" = "YOUR-DB-USER"
"database.password" = "YOUR-DB-PASSWORD"
"database.server.id" = "12345"
"database.server.name" = "YOUR-SERVER-NAME"
"database.hostname" = "YOUR-AURORA-ENDPOINT"
"database.port" = "3306"
# Schema and converter settings
"key.converter.schemas.enable" = "false"
"value.converter.schemas.enable" = "false"
# Table and database filtering
"table.include.list" = "YOUR-DATABASE.table1,YOUR-DATABASE.table2"
"database.include.list" = "YOUR-DATABASE"
# Snapshot configuration
"snapshot.mode" = "initial"
# Schema history configuration
"schema.history.internal.kafka.topic" = "internal.dbhistory.YOUR-TOPIC-PREFIX"
"schema.history.internal.kafka.bootstrap.servers" = "YOUR-MSK-BOOTSTRAP-SERVERS"
# IAM authentication for schema history topic
"schema.history.internal.producer.sasl.mechanism" = "AWS_MSK_IAM"
"schema.history.internal.consumer.sasl.mechanism" = "AWS_MSK_IAM"
"schema.history.internal.producer.sasl.jaas.config" = "software.amazon.msk.auth.iam.IAMLoginModule required;"
"schema.history.internal.consumer.sasl.jaas.config" = "software.amazon.msk.auth.iam.IAMLoginModule required;"
"schema.history.internal.producer.sasl.client.callback.handler.class" = "software.amazon.msk.auth.iam.IAMClientCallbackHandler"
"schema.history.internal.consumer.sasl.client.callback.handler.class" = "software.amazon.msk.auth.iam.IAMClientCallbackHandler"
"schema.history.internal.consumer.security.protocol" = "SASL_SSL"
"schema.history.internal.producer.security.protocol" = "SASL_SSL"
}
}
Key Configuration Parameters
Snapshot Mode Configuration
The snapshot.mode parameter is crucial for determining how Debezium handles initial data capture. Here are the different options:
"snapshot.mode" = "initial" – Performs a full snapshot of all specified tables before starting to stream changes (recommended for new deployments).
"snapshot.mode" = "no_data" – Captures only the schema without historical data and starts streaming from the current binlog position immediately.
"snapshot.mode" = "when_needed" – Performs snapshot only if no previous offset exists, good for connector restarts.
"snapshot.mode" = "never" – Never performs snapshots, only streams changes (fastest startup but requires existing offset information).
Table and Database Filtering
You can control which databases and tables are included in CDC using these filtering configurations:
"database.include.list" = "YOUR-DATABASE" – Specifies which databases to monitor for changes (comma-separated list for multiple databases).
"table.include.list" = "YOUR-DATABASE.table1,YOUR-DATABASE.table2" – Defines specific tables to capture changes from, using the format database.table (reduces processing overhead by excluding unnecessary tables).
These filters are essential for:
- Performance optimization: Only capture changes from tables you actually need
- Security: Exclude sensitive tables from CDC streams
- Cost reduction: Minimize MSK topic storage and processing costs
- Compliance: Control which data is replicated to downstream systems
Data Type Handling
"decimal.handling.mode" = "string" This configuration was critical for solving decimal field issues. By default, Debezium encodes high-precision decimals as binary to preserve exact precision, but this causes problems in Redshift. Setting it to “string” makes Debezium send readable decimal strings that can be properly cast in Redshift.
"include.schema.changes" = "true" Captures DDL changes (CREATE, ALTER, DROP statements) in addition to DML changes, providing complete database evolution tracking.
Topic and Naming Configuration
"topic.prefix" = "YOUR-TOPIC-PREFIX" This prefix is used for all Kafka topics created by Debezium. Topics follow the pattern: {topic.prefix}.{database}.{table}. Choose a meaningful prefix that identifies your data source.
"database.server.name" = "YOUR-SERVER-NAME" A logical identifier for the MySQL server. This becomes part of the topic naming and should be unique across your Debezium deployments.
MSK Connect Worker Configuration
I also configured the MSK Connect worker to optimize performance and data handling:
resource "aws_mskconnect_worker_configuration" "debezium_worker" {
name = "debezium-worker-config"
description = "Worker configuration for Debezium MySQL source connector"
properties_file_content = <<-EOT
key.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=false
offset.storage.topic=offsets_my_debezium_source_connector
EOT
}
This configuration ensures consistent data formatting across all connectors and disables schema information in the messages to reduce payload size.
Understanding Debezium Message Structure
Before diving into the challenges, it’s important to understand the structure of CDC events that Debezium produces. Each change event follows a standardized JSON format that provides comprehensive information about the database change. For detailed documentation on the Debezium JSON format, refer to the official Debezium JSON format documentation.
{
"before": {
"id": 111,
"name": "scooter",
"description": "Big 2-wheel scooter",
"weight": 5.18
},
"after": {
"id": 111,
"name": "scooter",
"description": "Big 2-wheel scooter",
"weight": 5.15
},
"source": {
"version": "2.4.0.Final",
"connector": "mysql",
"name": "YOUR-SERVER-NAME",
"ts_ms": 1589362330904,
"snapshot": "false",
"db": "inventory",
"sequence": null,
"table": "products",
"server_id": 223344,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 484,
"row": 0,
"thread": null,
"query": null
},
"op": "u",
"ts_ms": 1589362330904,
"transaction": null
}
Message Structure Breakdown
"before" – Contains the row data before the change occurred (null for INSERT operations)
"after" – Contains the row data after the change occurred (null for DELETE operations)
"source" – Provides metadata about the change event, including:
- Database and table information
- Binlog position for tracking
- Timestamp when the change occurred
- Connector version and configuration details
"op" – Operation type indicator:
"c"= CREATE (INSERT)"u"= UPDATE"d"= DELETE"r"= READ (initial snapshot)
"ts_ms" – Timestamp in milliseconds when Debezium processed the event
"transaction" – Transaction metadata (if available)
This structure allows downstream consumers like Redshift to understand exactly what changed, when it changed, and how to process the data accordingly. The before and after fields are particularly useful for implementing upsert logic and tracking data evolution over time.
Testing and Validation: During development, I was able to directly examine the structure and format of JSON CDC events by creating a testing consumer and checking the ingestion of CDC events via the bastion host. This approach allowed me to validate the data format and identify the data type issues described in the challenges section. I’ll elaborate on the testing consumer setup and validation techniques in more detail in a future episode.
Challenges and Solutions
While Debezium’s configuration appears straightforward, I encountered several critical challenges during implementation that required specific solutions. These issues are common in CDC pipelines, and understanding them will save you significant troubleshooting time.
Data Type Handling Challenges
During implementation, I discovered two major data type handling issues that affected data quality in Redshift. These challenges highlight the importance of understanding how Debezium processes different MySQL data types.
Challenge 1: Decimal Fields Encoded as Base64
Problem: Debezium converts high-precision decimal fields to Base64-encoded binary strings, causing NaN values in Redshift.
Example:
- MySQL:
order_price: 40.123 - CDC event:
"order_price": "Plo3FQ9H6dUAAA==" - Redshift result:
NaN
Solution: Configure Debezium to send decimals as strings:
"decimal.handling.mode" = "string"
Result:
- CDC event:
"order_price": "40.123456" - Redshift casting:
payload.after.order_price::DECIMAL(26,22)✓
Challenge 2: DateTime Fields as Epoch Milliseconds
Problem: Debezium converts MySQL DATETIME fields to epoch milliseconds, which Redshift treats as literal numbers instead of timestamps.
Example:
- MySQL:
purchase_date: "2017-09-09 16:20:41" - CDC event:
"purchase_date": 1753279941000 - Redshift casting:
::TIMESTAMP→ incorrect result
Solution: Convert epoch milliseconds to proper timestamps in Redshift stored procedures:
-- Before (Incorrect)
payload.after.purchase_date::TIMESTAMP
-- After (Correct)
DATEADD(second, payload.after.purchase_date::BIGINT / 1000, '1970-01-01 00:00:00'::TIMESTAMP)
Result: 2017-09-09 16:20:41
Note: Mode details to come about Redshift setup in the next episode.
Configuration Management Challenges
Beyond data type issues, I also encountered operational challenges during development that are important to understand for production deployments.
Challenge 3: Configuration Changes Not Taking Effect
Problem: During development, I encountered situations where configuration changes to the Debezium connector were not taking effect, even after applying them through Terraform or the AWS Console.
Root Cause: MSK Connect connectors sometimes cache configuration or fail to reload certain parameters without a complete restart.
Solution: For critical configuration changes during development, I had to destroy and recreate the connector.
Production Deployment Architecture
Now that we’ve covered the configuration and challenges, let’s look at how to deploy Debezium in a production-ready environment using MSK Connect. This section covers the complete deployment architecture from plugin management to scaling and security.
Custom Plugin Configuration
Debezium requires a custom plugin to be deployed to MSK Connect. I implemented this through a three-step process using Terraform:
Step 1: Provision S3 Bucket for Plugin Storage
module "debezium_plugin_s3_bucket" {
source = "terraform-aws-modules/s3-bucket/aws"
bucket = "YOUR-DEBEZIUM-PLUGIN-BUCKET"
# Enable versioning for plugin management
versioning = {
enabled = true
}
# Block public access for security
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}
Step 2: Upload Debezium Plugin to S3 After provisioning the S3 bucket, I manually uploaded the Debezium MySQL connector plugin ZIP file. You can download the official plugin from the Debezium releases page (e.g., debezium-connector-mysql-2.4.0.Final-plugin.zip).
Step 3: Create MSK Connect Custom Plugin
resource "aws_mskconnect_custom_plugin" "debezium" {
name = "debezium-mysql-plugin"
content_type = "ZIP"
location {
s3 {
bucket_arn = module.debezium_plugin_s3_bucket.s3_bucket_arn
file_key = "debezium/debezium-connector-mysql-3.1.2.Final-plugin.zip"
}
} depends_on = [module.debezium_plugin_s3_bucket]
}
The plugin ZIP file contains all necessary Debezium MySQL connector JAR files and dependencies. The MSK Connect custom plugin references the uploaded file in S3, making it available for connector deployments.
Capacity and Scaling Configuration
I configured MSK Connect with autoscaling to handle varying workloads:
capacity {
autoscaling {
max_worker_count = 2
mcu_count = 1
min_worker_count = 1
scale_in_policy {
cpu_utilization_percentage = 20
}
scale_out_policy {
cpu_utilization_percentage = 80
}
}
}
This configuration:
- Starts with 1 worker (minimum cost)
- Scales up to 2 workers when CPU exceeds 80%
- Scales down when CPU drops below 20%
- Each worker has 1 MCU (MSK Connect Unit) providing 1 vCPU and 4GB RAM
Security and IAM Configuration
The MSK Connect service requires comprehensive IAM permissions to interact with MSK, Secrets Manager, and CloudWatch:
resource "aws_iam_policy" "msk_connect_debezium" {
name = "msk-connect-debezium-policy"
description = "Policy for MSK Connect Debezium connector"
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Sid = "KafkaAccess"
Effect = "Allow"
Action = [
"kafka-cluster:Connect",
"kafka-cluster:AlterCluster",
"kafka-cluster:DescribeCluster"
]
Resource = "arn:aws:kafka:REGION:ACCOUNT:cluster/YOUR-MSK-CLUSTER/*"
},
{
Sid = "KafkaTopicAccess"
Effect = "Allow"
Action = [
"kafka-cluster:DescribeTopic",
"kafka-cluster:WriteData",
"kafka-cluster:CreateTopic",
"kafka-cluster:ReadData"
]
Resource = "arn:aws:kafka:REGION:ACCOUNT:topic/YOUR-MSK-CLUSTER/*"
},
{
Sid = "SecretsAccess"
Effect = "Allow"
Action = [
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret"
]
Resource = "arn:aws:secretsmanager:REGION:ACCOUNT:secret:YOUR-DB-CREDENTIALS/*"
}
]
})
}
Conclusion
Successfully implementing Debezium for reliable CDC requires understanding both the configuration details and the real-world challenges you’ll encounter. The Debezium connector now reliably captures changes from Aurora MySQL and streams them to MSK topics in a format that Redshift can properly consume. We’ve solved the critical data type challenges and established a robust deployment architecture that can scale with your data volume.
Next Steps
In Episode 3, I’ll cover setting up a bastion host for secure access to MSK topics, enabling you to inspect CDC events, validate data formats, and troubleshoot your Debezium implementation during development.
Next Steps
This article is part of a comprehensive three-part series on implementing CDC streaming with Amazon Redshift, MSK, and Debezium:
Episode 1: Designing the End-to-End CDC Architecture — Learn about the overall architecture design, infrastructure setup, and foundational components, including Aurora MySQL, Amazon MSK, Redshift Serverless, and network security configurations.
Episode 2: Configuring Debezium Connector for Reliable CDC (Current Episode) Deep dive into Debezium configuration, data type challenges, deployment architecture, and production best practices.
Episode 3: Redshift Serverless Streaming Ingestion (Coming Soon) Comprehensive coverage of Redshift Serverless streaming ingestion configuration, performance optimization, and real-time analytics implementation.
Author
Noor Sabahi | Senior AI & Cloud Engineer | AWS Ambassador
#Debezium #CDC #MSKConnect #DebeziumConfiguration #AuroraMySQL #MSK #AWS #DataStreaming #Kafka