







Empowering Wind Farm Engineers with AI
A Hands-On Guide to Choosing the Perfect Turbine

Introduction
Choosing the right turbine for a wind farm is a high-stakes decision, with the potential to impact everything from energy output to the longevity of the farm itself. Wind farm engineers face a daunting challenge: sifting through countless datasheets, each packed with technical specifications, to find the turbine that perfectly matches the environmental conditions of their site. But what if AI could make this process not only easier but more accurate?
In this post, we’ll explore how AI can empower wind farm engineers to make data-driven decisions with confidence. By leveraging advanced machine learning models, we’ll show you how to quickly analyze turbine datasheets, assess environmental factors like wind speed, and recommend the best turbine for your project – all through a fun, hands-on activity. Whether you’re a seasoned engineer or just curious about the intersection of AI and renewable energy, this guide will give you the tools you need to optimize turbine selection with ease.
Setting the Stage
Understanding the Challenge:
Wind farm engineering is as much about precision as it is about innovation. When selecting turbines for a new farm, engineers must consider a myriad of factors, from wind speed and direction to the technical specifications of the turbines themselves. Each site has unique conditions, and the wrong choice could mean underperformance or even operational risks. With dozens of datasheets to sift through, each with its own set of intricate details, the task can become overwhelming.
AI to the Rescue:
This is where AI steps in to transform the decision-making process. Imagine having a virtual assistant that not only understands the technical jargon of turbine datasheets but can also cross-reference it with site-specific environmental data. By harnessing the power of machine learning, we can streamline the process of analyzing datasheets, making it faster and more accurate. This approach doesn’t just save time – it enables engineers to make smarter, data-backed decisions that maximize efficiency and safety on the farm.
In the next section, we’ll introduce you to the basic concepts and tools that make this possible, setting the foundation for the hands-on activity where we’ll see AI in action, helping you select the ideal turbines for your wind farm project.
Extracting and Processing Turbine Datasheets
Step 1: Extracting Text from PDFs
The first step in our journey is to extract the valuable information locked inside turbine datasheets, typically stored as PDFs. These documents contain all the crucial specifications and data we need, but in their raw form, they aren’t very search-friendly. To solve this, we’ll use Python and the PyPDF2 library to extract text from each PDF.
Here’s a simple function to do just that:
def extract_text_from_pdf(pdf_path):
with open(pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page_num in range(len(reader.pages)):
page = reader.pages[page_num]
text += page.extract_text()
return textThis function reads each page of a PDF file and compiles all the text into a single string. With this, we’re ready to handle multiple datasheets efficiently.
Step 2: Creating Searchable Documents
Once we’ve extracted the text from our PDFs, the next step is to convert this information into a format that allows for quick and accurate retrieval. We’ll create Document objects, which not only store the text but also include metadata, such as the filename, to help us keep track of the source.
Here’s how we can process an entire directory of PDFs:
def process_pdfs(directory_path):
documents = []
for filename in os.listdir(directory_path):
if filename.endswith('.pdf'):
pdf_path = os.path.join(directory_path, filename)
text = extract_text_from_pdf(pdf_path)
document = Document(page_content=text, metadata={"source": filename})
documents.append(document)
return documentsThis function scans a directory, extracts text from each PDF, and converts it into a Document object with relevant metadata. By the end of this step, we’ll have a collection of documents that are not only searchable but also tagged with their sources for easy reference.
With our turbine datasheets now digitized and organized, we’re ready to move on to building a powerful vector store, which will make retrieving the right information a breeze.
Building a Vector Store
Step 1: What is a Vector Store?
Before we dive into the code, let’s take a moment to understand what a vector store is and why it’s essential for our project. A vector store is a data structure that allows us to organize and retrieve documents based on their content. By converting our documents into vectors – numerical representations that capture the meaning and context of the text – we can quickly search through large collections of data to find the most relevant information. This is crucial when dealing with technical datasheets, where you need to find specific details fast.
Step 2: Creating and Saving the Vector Store
Now that we have a collection of processed documents, the next step is to create a vector store that will allow us to efficiently search through them. We’ll use FAISS (Facebook AI Similarity Search) for this task, paired with Bedrock embeddings to convert our documents into vectors.
Here’s how you can create and save a vector store:
def create_vector_store(documents, vector_store_path, embeddings):
if os.path.exists(vector_store_path):
vector_store = FAISS.load_local(vector_store_path, embeddings, allow_dangerous_deserialization=True)
else:
vector_store = FAISS.from_documents(documents, embeddings)
vector_store.save_local(vector_store_path)
return vector_storeThis function does two things:
- Load an Existing Vector Store: If a vector store already exists at the specified path, it loads it into memory. This saves time by avoiding the need to recreate the vector store from scratch every time.
- Create a New Vector Store: If the vector store doesn’t exist, it generates one from the documents using the provided embeddings and saves it for future use.
Step 3: Putting It All Together
With our vector store in place, we now have a powerful tool that can search through our turbine datasheets in seconds. This enables us to quickly find relevant documents based on queries, making it easier to compare turbines and select the best option for our wind farm.
Here’s an example of how to use the vector store:
directory_path = './'
documents = process_pdfs(directory_path)
embeddings = BedrockEmbeddings(region_name=REGION_NAME)
vector_store_path = './vector_store.faiss'
vector_store = create_vector_store(documents, vector_store_path, embeddings)In this example, we process the PDFs in a directory, generate embeddings for them, and create (or load) a vector store. This sets the stage for deploying our AI agent in the next section, where we’ll put all of this to work in making data-driven turbine recommendations.
Deploying the Wind Turbine Expert Agent
Step 1: Setting Up the AI Agent
With our vector store ready, it’s time to introduce the AI agent that will act as your personal wind turbine expert. This agent is designed to answer complex queries about turbine selection by leveraging the data stored in the vector store. We’ll use the ChatBedrock model, configured to operate with a specific prompt template that guides its behavior.
Here’s how to set up the agent:
def react_agent(retriever):
llm = ChatBedrock(model_id=LLM_MODEL, region_name=REGION_NAME, model_kwargs={"temperature": TEMPERATURE})
retriever_tool = create_retriever_tool(retriever, name="Wind Turbine Datasheets", description="A tool that retrieves wind turbine datasheets based on a query")
tools = [retriever_tool, wind_speed_retriever]
template = """
You are a wind turbine expert armed with datasheets of turbines. Answer questions based solely on
the information provided in the datasheets (DO NOT MAKE UP ANY TURBINE OPTIONS).
You should always try to find the windspeed using your tool.
Always use datasheets and use the tool below to get them.
You should first look up the windspeed, then look at the datasheets.
After you have observed both, you are ready for your final answer.
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
If you are recommending a turbine, only recommend one.
FINAL RESPONSE FORMAT INSTRUCTIONS - ONLY RETURN A JSON RESPONSE
----------------------------
{{
"Response": {{
"turbine_name": "Turbine Name",
"turbine_description": "Turbine Description",
"theoretical_power_output": [] Provide pairs of power output and wind values so that we can interpolate
"Rated Power Output": in kW
"Maximum Safe Wind Speed": in m/s
"Expected_wind_speed": in m/s
}}
}}
Begin! And remember to only return the JSON response format above.
Question: {input}
Thought:{agent_scratchpad}
"""
prompt = PromptTemplate.from_template(template)
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, handle_parsing_errors=True, verbose=True)
return agent_executorIn this setup:
- LLM Configuration: We configure the
ChatBedrockmodel, setting the temperature to control the creativity of the responses. - Tools Integration: The agent is equipped with tools like the
retriever_tool, which accesses the vector store to fetch relevant turbine datasheets based on a query. - Prompt Template: The template defines how the agent should process queries and format its responses, ensuring consistency and relevance in the output.
Step 2: Making Data-Driven Decisions
With the agent ready, we can now ask it to help us select the best turbines for specific wind farm locations. The agent will consider all available data, including wind speeds and turbine specs, to make informed recommendations.
Here’s how to invoke the agent:
retriever = vector_store.as_retriever()
agent = react_agent(retriever)
res = agent.invoke({"input": "I am looking to start a wind turbine farm can you suggest to me some turbines? "
"The farm is located at 40.7128° N, 74.0060° W"})
res = res['output']
print(res)In this example:
- Retrieve Relevant Data: The agent uses the vector store to pull up relevant datasheets based on the query.
- Analyze and Recommend: The agent analyzes the data, cross-references it with the specified location’s wind conditions, and recommends the most suitable turbine.
Step 3: Example Use Case
To see the agent in action, let’s consider a real-world scenario: You want to start a wind farm in New York City (coordinates: 40.7128° N, 74.0060° W). By feeding this query to the agent, it will retrieve relevant turbine datasheets, analyze the wind conditions, and recommend a specific turbine that best fits the site.
The response, formatted in JSON, will provide detailed information about the recommended turbine, including its name, description, power output, and safe wind speed range. This makes it easy for you to make informed decisions without manually sifting through technical documents.
Visualizing the Wind Farm
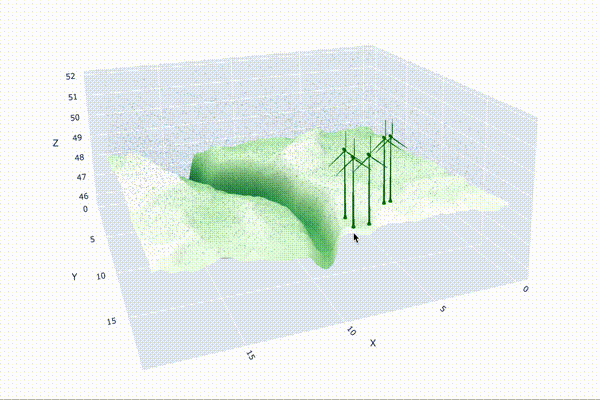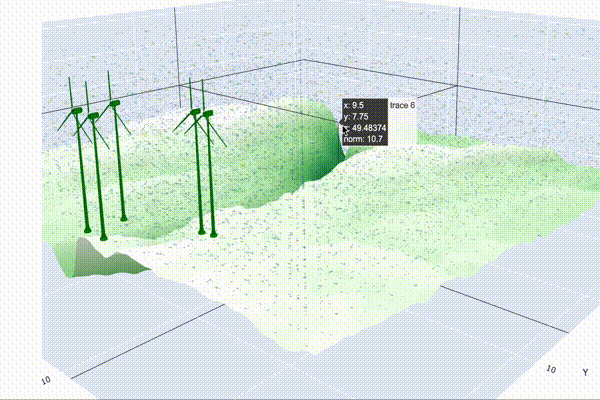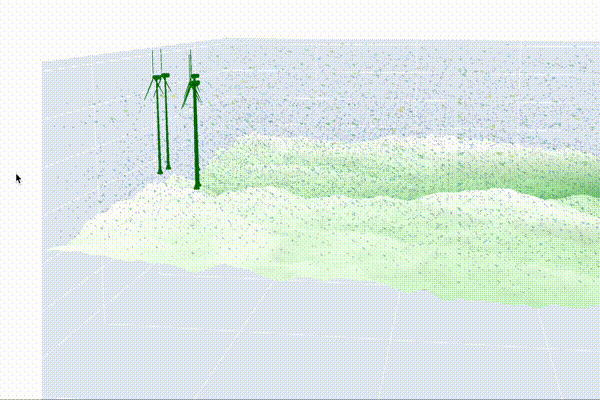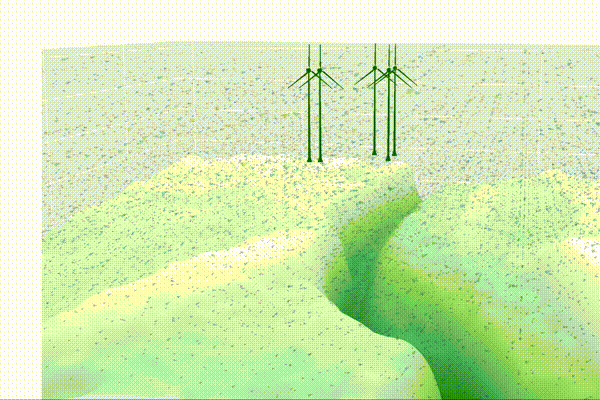
Step 1: Simulating Wind Conditions
After selecting the ideal turbines for our wind farm, the next step is to visualize how these turbines will perform under real-world conditions. To achieve this, we’ll simulate the wind vector field across our site using a 3D mesh of the terrain. By computing the wind flow over the terrain for a given far-field airspeed vector provided by meteorological data, we can gain a detailed understanding of how wind speeds and directions vary across the farm.
It’s important to note that directly solving the Navier-Stokes equations, which govern fluid dynamics, is computationally intensive and complex. Instead, we make a significant simplification by using a potential flow model. This approach, while less precise than a full Navier-Stokes solution, allows us to efficiently simulate wind flow across the terrain with reasonable accuracy for our purposes.
Here’s the function that computes the wind vector field:
def compute_wind_vector_field(mesh_path, global_wind_vector):
# Load the mesh
mesh = Gmsh3D(mesh_path)
# Initialize the potential variable
potential = CellVariable(mesh=mesh, name='potential', value=0.)
# Define boundary conditions for the potential flow
x, y, z = mesh.faceCenters
xmin = x.min()
xmax = x.max()
ymin = y.min()
ymax = y.max()
zrange = z.max() - z.min()
maskUp = (mesh.exteriorFaces & (
z >= z.max() - zrange / 2)) | mesh.facesLeft | mesh.facesRight | mesh.facesTop | mesh.facesBottom
maskDown = (mesh.exteriorFaces & (z <= z.max() - zrange / 2) & (x < xmax) & (x > xmin) & (y < ymax) & (y > ymin))
potential.constrain(global_wind_vector[0] * x + global_wind_vector[1] * y, where=maskUp)
potential.faceGrad.constrain(0 * mesh.faceNormals, where=maskDown)
# Define the equation for potential flow
eq = DiffusionTerm(coeff=1.0) == 0
eq.solve(var=potential)
# Extract the gradient of the potential to get the wind vector field
grad_potential = potential.grad
u = grad_potential[0].value
v = grad_potential[1].value
w = grad_potential[2].value
cellx, celly, cellz = mesh.cellCenters
return cellx, celly, cellz, u, v, wStep 2: Placing the Wind Turbines
Once we have our wind vector field, the next step is to strategically place our wind turbines on the terrain. To optimize energy production, we’ll position the turbines at the highest elevation points, where wind speeds are generally the strongest. Using a 3D mesh of the turbine, we can then visualize how the turbines will look on the landscape.
Here’s the function that plots the wind turbines:
def plot_windmill(fig, x_center, y_center, z_max, windmill_scale=0.1):
# Load the mesh from the .glb file
mesh = trimesh.load("./uploads_files_3307892_windTurbineBasic.glb", force="mesh")
# Extract the list of vertices
vertices = mesh.vertices # (n_vertices, 3)
# Extract the list of triangles (indices into the vertices list)
triangles = mesh.faces # (n_triangles, 3)
# Extract x, y, and z coordinates
x, y, z = vertices[:, 0], vertices[:, 1], vertices[:, 2]
# the mesh is rotated so we have to flip the y and z
oldy = y
y = z
z = oldy
# Scale the windmill
x = x * windmill_scale
y = y * windmill_scale
z = (z/10)
# translate the windmill to the specified point in the DEM
x = x + x_center
y = y + y_center
z = z + z_max
# Plot the windmill using triangular_mesh
fig.add_trace(go.Mesh3d(
x=x, y=y, z=z,
i=triangles[:, 0], j=triangles[:, 1], k=triangles[:, 2],
color='green', opacity=0.8
))Step 3: Bringing It All Together
Now that we have the wind vector field and turbine placement functions, it’s time to visualize the entire wind farm. We’ll simulate the landscape, plot the turbines, and display the wind vectors to give a complete picture of how the wind farm will look and perform. The visualization will also include a prediction of the total power output based on the wind conditions.
Here’s the function to show the wind farm:
def show_wind_farm(num_windmills=5):
# Define the relative path to the file
relative_path = './6-16-34-30.laz'
raster_path = './temp.tif'
global_wind_vector = np.array([1, 1])
global_wind_vector = global_wind_vector/np.linalg.norm(global_wind_vector)
wind_x, wind_y, wind_z, wind_u, wind_v, wind_w = compute_wind_vector_field('./elevation_surface_mesh.msh', global_wind_vector * EXPECTED_WIND_SPEED)
wind_magnitudes = np.sqrt(wind_u**2 + wind_v**2 + wind_w**2)
# Convert the relative path to an absolute (global) path
absolute_path = os.path.abspath(relative_path)
wbt = whitebox.WhiteboxTools()
wbt.lidar_idw_interpolation(i=absolute_path, output=os.path.abspath(raster_path),
parameter="elevation",
returns="last",
resolution=1,
exclude_cls='1')
wbt.fill_missing_data(i=os.path.abspath(raster_path),
output=os.path.abspath(raster_path),
filter=11,
weight=2,
no_edges=False)
idw_dem = rxr.open_rasterio(raster_path, masked=True)
numpy_dem = idw_dem[0, :, :].to_numpy()
smoothed_dem = gaussian_filter(numpy_dem, sigma=3)
xmin = wind_x.min()
xmax = wind_x.max()
ymin = wind_y.min()
ymax = wind_y.max()
zmin = smoothed_dem.min()
zmax = smoothed_dem.max()
zmaxair = wind_z.max()
# Create the surface mesh
fig = go.Figure(data=[go.Surface(z=smoothed_dem.T, x=np.linspace(xmin, xmax, smoothed_dem.shape[1]),
y=np.linspace(ymin, ymax, smoothed_dem.shape[0]), colorscale='greens_r')])
local_peaks_mask = detect_local_peaks(smoothed_dem)
peaked_dem = smoothed_dem * local_peaks_mask
# Get the n highest points in the DEM
n = num_windmills
flat_indices = np.argpartition(peaked_dem.flatten(), -n)[-n:]
y_indices, x_indices = np.unravel_index(flat_indices, peaked_dem.shape)
# Get the coord that these indices relate to
xcoords = np.linspace(xmin, xmax, smoothed_dem.shape[1])
ycoords = np.linspace(ymin, ymax, smoothed_dem.shape[0])
x_centers = xcoords[x_indices]
y_centers = ycoords[y_indices]
# Plot windmills at the n highest points
z_max = smoothed_dem.max()
z_min = smoothed_dem.min()
totalPower = 0
for y_center, x_center in zip(y_centers, x_centers):
#predict the power output of this turbine
center = np.array([x_center, y_center])
wind_columns = np.vstack([wind_x, wind_y]).T
distances = np.linalg.norm(wind_columns - center, axis=1)
wind_columnn_inds = np.where(distances <= 0.5)[0]
wind_magnitude = np.mean(wind_magnitudes[wind_columnn_inds])
predictedPower = np.interp(wind_magnitude, POWERS_Array[:, 0], POWERS_Array[:, 1])
totalPower += predictedPower
plot_windmill(fig, x_center, y_center, z_max)
fig.add_trace(go.Cone(x=wind_x, y=wind_y, z=wind_z, u=wind_u, v=wind_v, w=wind_w, sizemode='absolute', sizeref=10, anchor='tail', colorscale='Viridis', showscale=False, opacity=0.2))
fig.update_layout(title=f"Total Power Prediction: {int(totalPower)}MW", width=1200, height=1200, autosize=False,
scene=dict(
xaxis_title='X',
yaxis_title='Y',
zaxis = dict(title='Z', range=[z_min, z_max + (z_max - z_min)])
))
fig.show()This function pulls everything together, creating a detailed 3D visualization of your wind farm. It displays the landscape, positions the turbines at optimal locations, and overlays wind vectors to show how the wind interacts with the turbines. The title of the plot even predicts the total power output, giving you an instant estimate of your farm’s performance.
By visualizing your wind farm in this way, you not only gain insights into the physical layout but also see the impact of wind patterns on power generation, making it easier to optimize your design for maximum efficiency.
Conclusion
In the fast-evolving world of renewable energy, making informed, data-driven decisions is more critical than ever. As we’ve explored in this guide, AI has the potential to transform how wind farm engineers approach the complex task of turbine selection. By leveraging machine learning models, vector stores, and advanced retrieval tools, we can process vast amounts of technical data quickly and accurately, ensuring that the turbines we choose are perfectly suited to their environment.
This hands-on activity demonstrated how to extract, organize, and analyze turbine datasheets using AI, culminating in a powerful tool that not only simplifies decision-making but also enhances the precision of your choices. Whether you’re setting up a new wind farm or optimizing an existing one, the ability to quickly access and interpret critical data can make all the difference.
As we move forward, the integration of AI in renewable energy will only grow more significant. We encourage you to take what you’ve learned here and apply it to your own projects, pushing the boundaries of what’s possible with data-driven turbine selection. The future of wind energy is bright – and with the right tools, you’re ready to harness it.