

Current and Future Trends with A Look at Recent HILF Events The consumption of energy and its transformation into electricity are essential …

Core Concepts and Value Propositions In the ever-evolving landscape of web development, efficient data fetching and manipulation have become paramount concerns. Traditional …
How and Why to Use Custom SageMaker Images If you have used SageMaker for data science modeling work, you have likely used …

ChatGPT generated image What Underfitting is and How to Test for It and Minimize its Impact Machine learning stands as a pivotal …

A document-devouring llama with Robyn wings that soars through your data! Performance Optimized Retrieval Augmented Generation Introduction In today’s data-driven environment, organizations …
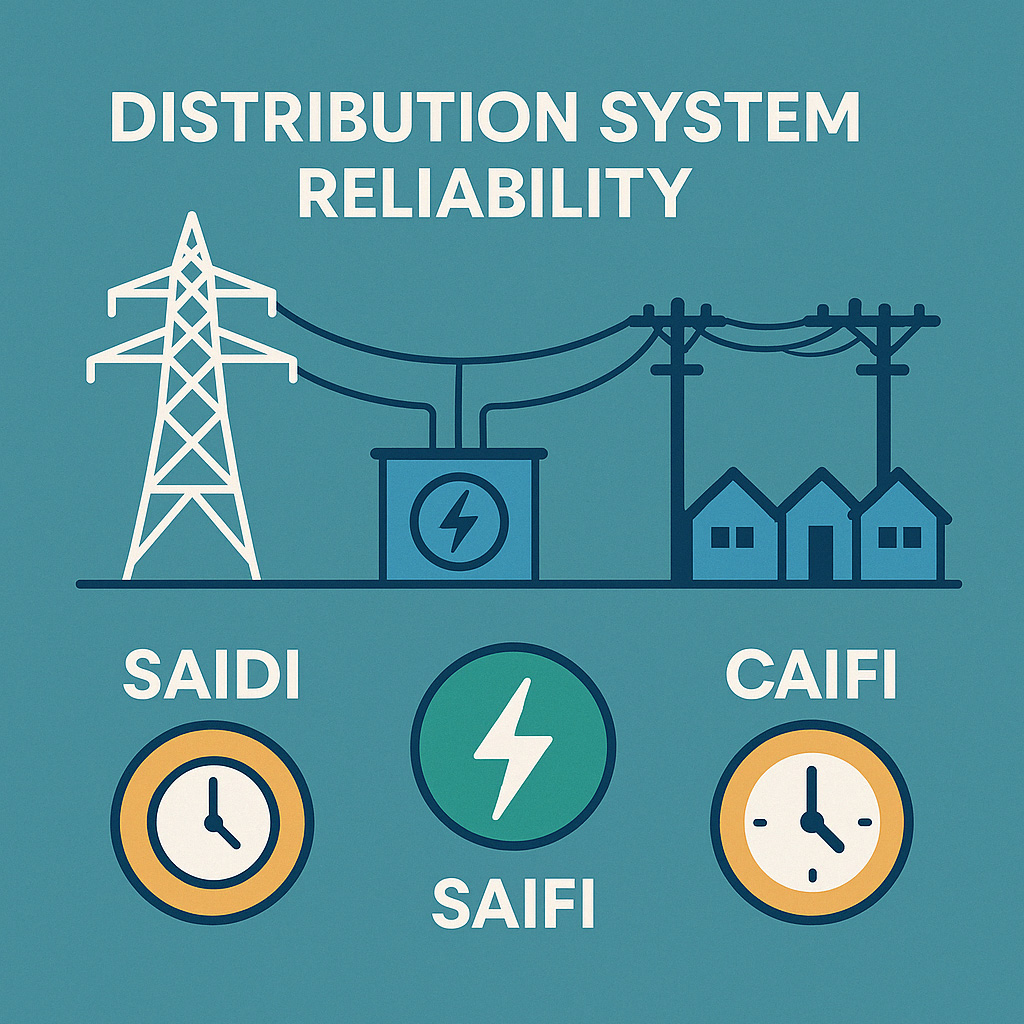
Introduction Electricity is an essential part of modern life, powering homes, businesses, and industries. A reliable electrical distribution system ensures continuous power …