

A Deep Dive into an AWS OpenSearch + Bedrock + Chainlit RAG Pipeline
Introduction
This article explains how to build a question-answering system that processes PDF and Video Text Track (VTT) files, index them in AWS OpenSearch, and serve fast answers to users. It uses AWS Bedrock (Anthropic Claude) for language processing and Chainlit for a chat-based interface; through this, the system achieves low-latency retrieval augmented generation (RAG). We also explore how to chunk documents for better search results, store vector embeddings, and invoke Claude Sonnet for real-time responses. Additionally, we compare using LangChain with more direct Bedrock calls to illustrate performance trade-offs and keep response times under two seconds. This article is based on some recent work we at New Math Data did recently, but it genericizes the concepts to and architecture to product client confidentiality.
Motivation and Requirements
Building a real-time document Q&A system requires balancing speed, accuracy, and flexibility. Ingesting PDFs and VTT files at scale demands efficient parsing and text chunking, while ensuring that queries against this data return results within two-second. Traditional search solutions, such as keyword-based retrieval, struggle with context awareness and often return incomplete answers. Meanwhile, large language models excel at extracting nuanced insights but can become slow or unwieldy with large document sets.
To address these challenges, this project uses three key components: AWS OpenSearch for scalable indexing and vector-based retrieval, AWS Bedrock (Anthropic Claude) for language modeling and Chainlit for the chat interface. By combining these components in a Retrieval Augmented Generation (RAG) workflow, the system achieves low-latency, high-quality responses. The approach leverages streaming from Claude Sonnet to ensure near-immediate start times, while selective chunking keeps the model context compact.
The remainder of this post walks through the architectural design, deployment details, and performance optimizations that enable a smooth experience from ingestion to real-time conversation. The goal is to outline key decisions — such as chunking strategies, indexing schemas, and direct Bedrock client calls — in a concise manner, highlighting both potential pitfalls and best practices for a similar setup.
Architecture Overview
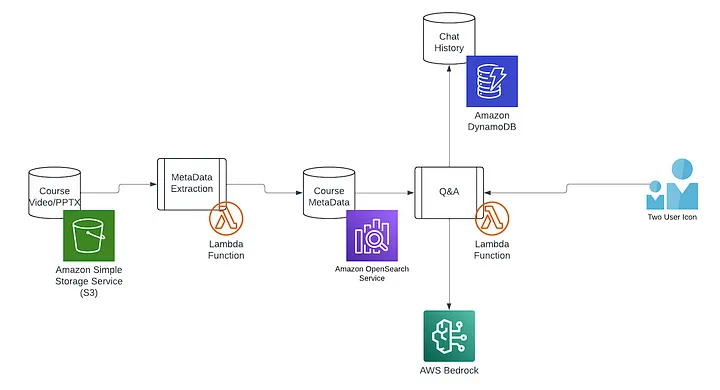
This system relies on a Retrieval Augmented Generation (RAG) pattern, where relevant chunks of text are first retrieved from AWS OpenSearch and then sent to Anthropic Claude for generation. AWS Lambda functions process and index PDF and VTT files, extracting text and generating vector embeddings that OpenSearch can query in real time. Chainlit provides the chat interface, forwarding user input to the backend for retrieval and language model responses.
The workflow ensures sub-two-second response times by limiting each operation to minimal overhead. OpenSearch is optimized for quick vector searches, while Claude Sonnet streams partial answers back to the front-end almost immediately. Additionally, the design supports both a LangChain-based approach for rapid prototyping and a direct Bedrock client approach for environments where you need more granular control over network calls and performance.
Data Ingestion and Indexing
Below is an example workflow for parsing, chunking, embedding, and indexing text from both PDFs and VTT files. The snippets show a minimal AWS Lambda function flow for ingestion. For brevity, certain details (such as file handling and AWS credential management) are omitted.
Parsing PDF and VTT Files
import os
import io
import pypdf
from webvtt import WebVTT
def extract_text_from_pdf(pdf_file_path: str) -> str:
"""Extract all text from a PDF using pypdf."""
text_content = []
with open(pdf_file_path, 'rb') as f:
reader = pypdf.PdfReader(f)
for page in reader.pages:
text_content.append(page.extract_text())
return "\n".join(text_content)
def extract_text_from_vtt(vtt_file_path: str) -> str:
"""Extract all text from a VTT (Web Video Text Tracks) file."""
text_content = []
for caption in WebVTT().read(vtt_file_path):
text_content.append(caption.text)
return "\n".join(text_content)
Chunking the Extracted Text
Splitting large documents into smaller chunks helps keep context windows manageable for OpenSearch and the language model.
def chunk_text(text: str, chunk_size: int = 1000, overlap: int = 200) -> list:
"""
Break text into chunks of `chunk_size` characters with `overlap`.
Returns a list of text segments.
"""
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunk = text[start:end]
chunks.append(chunk)
start += chunk_size - overlap
return chunks
Generating Embeddings
Below are two approaches for creating embeddings: one using LangChain (with a hypothetical Bedrock Embedding class) and one using a direct Bedrock client call. You will need to adjust model IDs and parameters based on your environment.
1) Using LangChain’s Integration
from langchain.embeddings import BedrockEmbeddings # Example only; actual class name may differ
def generate_embeddings_langchain(chunks: list) -> list:
"""
Uses LangChain's Bedrock embeddings class to transform text chunks.
"""
# Assume a LangChain embedding class that supports AWS Bedrock
bedrock_embed = BedrockEmbeddings(model_id="anthropic.embedding-model")
embeddings = bedrock_embed.embed_documents(chunks)
return embeddings
2) Using the Bedrock Client Directly
import boto3
bedrock_client = boto3.client("bedrock-runtime", region_name="us-east-1")
def generate_embeddings_direct(chunks: list) -> list:
"""
Directly calls Bedrock to get embeddings for each chunk.
"""
embeddings = []
for chunk in chunks:
response = bedrock_client.invoke_model(
modelId="anthropic.embedding-model", # e.g., "anthropic.claude-v1"
body={"text": chunk}
)
vector = response["vectorEmbeddings"]
embeddings.append(vector)
return embeddings
Writing to OpenSearch
After obtaining embeddings, store both the text and vector data in OpenSearch. In production, you might use an official AWS library for OpenSearch, but here we show a simple requests example:
import requests
import json
OPENSEARCH_URL = "https://.aws.com"
INDEX_NAME = "documents"
def index_documents_in_opensearch(chunks: list, embeddings: list):
"""
Index documents into AWS OpenSearch with both text and vector fields.
"""
for i, chunk in enumerate(chunks):
doc_body = {
"text": chunk,
"vector": embeddings[i]
}
response = requests.post(
f"{OPENSEARCH_URL}/{INDEX_NAME}/_doc",
headers={"Content-Type": "application/json"},
data=json.dumps(doc_body)
)
if response.status_code not in [200, 201]:
print(f"Failed to index doc: {response.text}")
Putting It All Together in a Lambda Handler
Below is a simplified Lambda handler that:
- Detects if the file is a PDF or VTT.
- Extracts text and chunks it.
- Generates embeddings (direct Bedrock approach).
- Writes indexed data to OpenSearch.
def lambda_handler(event, context):
# 1. Determine file type & retrieve from S3 (not shown)
file_path = "/tmp/input_file" # local temp path in Lambda
# 2. Extract text
if file_path.endswith(".pdf"):
text = extract_text_from_pdf(file_path)
elif file_path.endswith(".vtt"):
text = extract_text_from_vtt(file_path)
else:
raise ValueError("Unsupported file type")
# 3. Chunk and embed
chunks = chunk_text(text)
embeddings = generate_embeddings_direct(chunks)
# 4. Index into OpenSearch
index_documents_in_opensearch(chunks, embeddings)
return {"status": "success", "chunks_indexed": len(chunks)}
With this workflow, newly uploaded PDF or VTT files are processed automatically by the Lambda function, and the resulting text chunks and embeddings become immediately searchable in AWS OpenSearch. The following sections outline how these indexed chunks are retrieved during chat interactions, as well as how we leverage AWS Bedrock (Anthropic Claude) to provide near real-time, streaming answers.
Retrieval and Chat Flow
Once documents are indexed, queries can be routed through Chainlit to retrieve the most relevant chunks from AWS OpenSearch before passing them to Anthropic Claude in Bedrock. This RAG design ensures contextually accurate answers and near-instant response starts. Below is a sample flow illustrating both a LangChain-based approach and a direct Bedrock client approach.
1) Querying OpenSearch for Relevant Chunks
A typical flow issues a vector similarity query to OpenSearch, returning the most relevant chunks:
import requests
import json
OPENSEARCH_URL = "https://.aws.com"
INDEX_NAME = "documents"
def retrieve_relevant_chunks(user_query: str, top_k: int = 3) -> list:
"""
Performs a vector search in OpenSearch to find top_k relevant chunks.
Assumes we have an embedding function for user_query below.
"""
user_query_vector = embed_query_direct(user_query) # or embed_query_langchain(user_query)
query_body = {
"size": top_k,
"query": {
"knn": {
"vector": {
"vector": user_query_vector,
"k": top_k
}
}
}
}
response = requests.post(
f"{OPENSEARCH_URL}/{INDEX_NAME}/_search",
headers={"Content-Type": "application/json"},
data=json.dumps(query_body)
)
hits = response.json()["hits"]["hits"]
# Extract relevant text from hits
chunks = [hit["_source"]["text"] for hit in hits]
return chunks
def embed_query_direct(query: str) -> list:
"""
Example of using a direct Bedrock call to embed a user query.
"""
import boto3
bedrock_client = boto3.client("bedrock-runtime", region_name="us-east-1")
response = bedrock_client.invoke_model(
modelId="anthropic.embedding-model",
body={"text": query}
)
return response["vectorEmbeddings"]
def embed_query_langchain(query: str) -> list:
"""
Example of using a LangChain-based approach for embedding.
"""
from langchain.embeddings import BedrockEmbeddings
bedrock_embed = BedrockEmbeddings(model_id="anthropic.embedding-model")
return bedrock_embed.embed_query(query)
2) Composing a Prompt with Retrieved Chunks
To provide context for the language model, combine the user’s query with retrieved chunks:
def compose_prompt(user_query: str, relevant_chunks: list) -> str:
"""
Create a prompt that includes relevant chunks.
You can format as a system message or user message, depending on your usage of Bedrock.
"""
context_section = "\n\n".join(relevant_chunks)
prompt = f"""
You are an AI assistant. Use the context below to answer the user's question.
Context:
{context_section}
Question:
{user_query}
Answer:
"""
return prompt
3) Invoking Anthropic Claude for Streaming Answers
Below is a simplified direct Bedrock call that streams a response from Claude. In production, you’d handle partial chunks of text in a streaming fashion.
import boto3
def stream_claude_response(prompt: str):
"""
Demonstrates calling Claude for a streaming response.
In practice, you'd integrate partial outputs into your Chainlit interface.
"""
bedrock_client = boto3.client("bedrock-runtime", region_name="us-east-1")
response = bedrock_client.invoke_model(
modelId="anthropic.claude-v1",
body={"prompt": prompt, "max_tokens_to_sample": 512, "stream": True}
)
# Example pseudo-code for reading a streaming response
for event in response["events"]:
chunk = event["chunk"]
yield chunk
If you choose to integrate with LangChain, you’d leverage a built-in streaming callback handler instead. However, for performance-critical applications, the direct approach often yields lower latency by reducing overhead.
4) Integrating with Chainlit
Chainlit simplifies building a conversational interface. Below is a skeleton example of how you might wire everything together:
# chainlit_app.py
import chainlit as cl
@cl.on_message # This decorator listens for user input
async def main(user_query: str):
# 1. Retrieve top chunks
chunks = retrieve_relevant_chunks(user_query)
# 2. Compose prompt
prompt = compose_prompt(user_query, chunks)
# 3. Stream response
# Using direct streaming from Claude
streaming_answer_generator = stream_claude_response(prompt)
# 4. Yield partial responses to the UI
partial_answer = ""
for chunk in streaming_answer_generator:
partial_answer += chunk
await cl.Message(content=partial_answer).send()
# Optionally, finalize the answer message in one shot
# await cl.Message(content=partial_answer).send(end_of_conversation=True)
When a user sends a message, the system retrieves relevant chunks from OpenSearch, crafts a prompt with those chunks, and streams the response from Claude back to the chat. This architecture combines minimal overhead with the potential for near-immediate partial responses — often under two seconds from query to first tokens.
With this retrieval pipeline in place, you have a fast, scalable way to chat with any PDF or VTT content you’ve indexed. The final section explores additional optimizations and best practices for production environments.
Optimizations and Best Practices
High performance in RAG depends on careful tuning across several layers. Below are key considerations and potential improvements to maintain or improve sub-two-second response times:
Streamlining OpenSearch Queries
- Vector Index Settings: Adjust parameters (e.g., approximate kNN settings, shard and replica configurations) to minimize search latency. Test different dimension sizes and similarity algorithms to find the sweet spot for your data size and query volume.
- Batching: If you anticipate handling multiple concurrent queries, consider batching embedding or search requests where possible to reduce overhead. However, ensure batching does not introduce unacceptable latency for smaller user requests.
Reducing Latency in Bedrock Calls
- Reuse the Client: Instead of creating a new Bedrock client on every request, instantiate it once (in a global scope or an initialization function). Repeated client instantiation can add unnecessary overhead.
- Tune Model Parameters: The number of tokens requested, temperature settings, and other model parameters can affect response generation speed. Smaller context windows and more constrained parameters may improve latency.
- Use Streaming Wisely: For near-instant “first token” responses, ensure your client library and front-end are configured to handle partial responses as soon as they arrive. This can dramatically enhance perceived speed for end users.
Employing Efficient Chunking
- Chunk Size: Overly large chunks can reduce retrieval accuracy and increase token usage in Bedrock, while too many tiny chunks can slow indexing and retrieval. You should experiment with chunk sizes that match your model’s context window and typical user queries.
- Overlapping Tokens: Overlapping text in adjacent chunks can boost recall, but too much overlap inflates storage and compute needs. A moderate overlap (e.g., 10–20% of chunk size) often suffices.
Monitoring and Logging
- OpenSearch Metrics: Track query latency, index latency, and cluster health to spot bottlenecks quickly. Increase resources or shards proactively if read or write latency spikes.
- Lambda and Chainlit Logs: Review Lambda execution times, especially around text parsing, embedding calls, and network overhead to Bedrock. Monitor Chainlit logs for front-end errors or excessive reconnection events.
- Load Testing: Simulate real-world traffic to verify your pipeline meets performance requirements under peak loads. Identify where concurrency or scaling challenges could occur (e.g., Lambda concurrency limits, bedrock throughput, or OpenSearch cluster capacity).
Scaling and Cost Management
- Autoscaling OpenSearch: Enable autoscaling or manually increase cluster size for high-demand periods. This helps maintain quick search responses without compromising on indexing throughput.
- Serverless Patterns: If using AWS Lambda for ingestion, ensure concurrency limits align with your input volume. For chat queries, consider dedicated inference endpoints or container-based solutions (e.g., ECS or EKS) if you need further control over concurrency or cost.
- Fine-Tuning: If you have large volumes of specific domain data, consider fine-tuning or instructing the model to reduce inference tokens. This can lower usage costs and speed up inference, provided the model supports customization.
By combining these techniques, you can keep response times under two seconds even as you scale to handle larger document sets or higher query volumes! The overall goal is to balance indexing efficiency, retrieval accuracy, and LLM inference speed in a way that gives users immediate, contextually rich answers, making your RAG application both robust and cost-effective.