







Creating Custom Hadoop Events in EventBridge on AWS
Introduction:
Event driven architecture as defined by Amazon is a system whose architecture uses events to trigger and communicate between decoupled services and is common in modern applications built with microservices. An event is a change in state or an update.
Event-driven architectures have three key components: event producers, event routers, and event consumers. A producer publishes an event to the router, which filters and pushes the events to consumers. Producer services and consumer services are decoupled, which allows them to be scaled, updated, and deployed independently.
Background:
Our Clients previous architecture involved an on-prem Hadoop cluster that refreshed data everyday on a schedule from their on-prem relational database. This would typically happen early morning. The Hadoop jobs would then push this data to the enterprises central data account to S3 buckets. The clients consuming AWS accounts would then wait a reasonable buffer period and then schedule their jobs that consume that data to run their scripts.
As you can imagine there are many inefficiencies in this approach:
- The consuming accounts are assuming the data was updated at the same time everyday. What if some of the datasets had an issue and the data wasn’t updated? What if the data took longer to update even considering the buffer period?
- The buffer period between the central account updating the data and the consuming account running their scripts is time wasted. What if we could run the scripts as soon as the data was updated in the central account?
Solution:
By moving towards an event driven architecture we would be able to save compute costs (scripts would only run when new data was truly available) and time (scripts will run as soon as new data is available). We are taking the assumptions out of the scheduled processes and over the numerous consuming accounts the value proposition is huge.
Design:
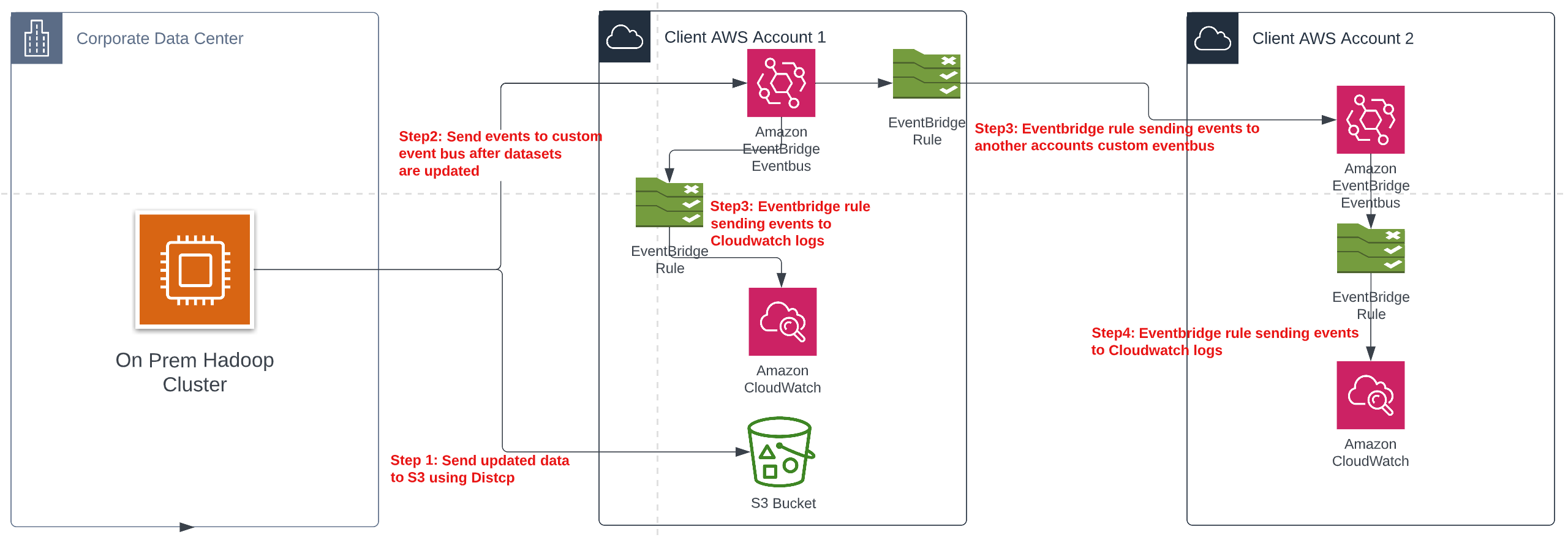
I’ll break down the architecture in steps:
Step 1:We created a custom python package utility that’s based off AWS’s Boto3 library and S3 Distcp. We implemented a bash script that would send data from Hadoop to S3 on a daily schedule.
<> "${TMPFILE}"
#See contents of tmp file
cat $TMPFILEStep 2:Once the data was updated the bash script would send an EventBridge event to an event bus in our central data account. The event has information that consumer accounts can use to target specific datasets they use in their downstream processes like Hadoop Database name, Hadoop table name.
{
"version": "0",
"id": "xxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx",
"detail-type": "schema_name",
"source": "source_of_data",
"account": "AWS account no",
"time": "2023-01-24T01:04:59Z",
"region": "AWS Region",
"resources": [],
"detail": {
"entity_platform": "Hadoop",
"entity_type": "Data_upload",
"entity_status": "finished",
"date_updated": "01-23-2023",
"src_path": "Path of Hadoop Table that was updated",
"src_database_name": "Hadoop DB Name",
"src_table_name": "Hadoop Table Name",
"tgt_path": "Path to S3 Folder",
"tgt_database_name": "Glue DB Name",
"tgt_table_name": "Glue Table Name",
"entity_additional_details": "Uploaded successfully"
}
} We set up a CloudWatch Log Group that gets triggered by an EventBridge Rule every-time a new event gets sent to our event-bus. This is useful to see the events actually flowing through and for debugging purposes incase some datasets weren't updated etc. Step 3:We set up multiple EventBridge rules each sending events from the central data accounts event-bus to the consuming accounts event-buses letting them know that their specific datasets have been updated. For reference data is shared to these consuming accounts using Resource Links and LakeFormation.
#Terraform code to set up a crossaccount event rule.
resource "aws_iam_role" "event_bus_invoke_crossaccount_event_bus" {
name = "event-bus-invoke-remote-event-bus"
assume_role_policy = <Step 4:Once the consuming accounts get the events, they can set up event rules on their side triggering their AWS processes like Lambdas, Glue Jobs, EMR scripts etc.
*/
Terraform Code for setting up a custom event bus and event rule that sends
events to a clodwatch log group so users can see the events being recieved.
*/
#Creates a custom eventbus
resource "aws_cloudwatch_event_bus" "messenger" {
name = "custom_event_name"
}
/*
Creates a CloudWatch event rule that sends all events that have
their source as the source defined in the event_pattern.
*/
resource "aws_cloudwatch_event_rule" "eventrule" {
name = "event_rule_name"
description = "Rule to see events being published from the custom eventbus to cloudwatch"
event_bus_name = aws_cloudwatch_event_bus.messenger.name
event_pattern = jsonencode(
{
"source": [
"source_of_data"
]
}
)
}
/*
Allows root users in the account to send events to the custom eventbus.
Consuming accounts can add the producer accounts in the "producer_account_ids"
variable allowing them to send events to the consuming accounts eventbus.
Allows root users to view and put rules and resources in the custom eventbus.
*/
data "aws_iam_policy_document" "eventbus" {
statement {
sid = "allow_account_to_put_events"
effect = "Allow"
actions = [
"events:PutEvents",
]
resources = [
aws_cloudwatch_event_bus.messenger.arn
]
principals {
type = "AWS"
identifiers = compact(concat([var.aws_account_id], var.producer_account_ids))
}
}
statement {
sid = "allow_account_to_manage_rules_they_created"
effect = "Allow"
actions = [
"events:DescribeRule",
"events:ListRules",
"events:ListTagsForResource",
"events:PutRule",
"events:PutTargets",
"events:DeleteRule",
"events:RemoveTargets",
"events:DisableRule",
"events:EnableRule",
"events:TagResource",
"events:UntagResource",
"events:ListTargetsByRule",
"events:ListTagsForResource"
]
resources = [
aws_cloudwatch_event_bus.messenger.arn,
aws_cloudwatch_event_rule.eventrule.arn
]
principals {
type = "AWS"
identifiers = [var.aws_account_id]
}
}
}
resource "aws_cloudwatch_event_bus_policy" "eventbus" {
policy = data.aws_iam_policy_document.eventbus.json
event_bus_name = aws_cloudwatch_event_bus.messenger.name
}
#event bridge event target CloudWatch
#Creates CloudWatch log group
resource "aws_cloudwatch_log_group" "logs" {
name = "/aws/events/eventbus_events/logs"
retention_in_days = 5
}
#Policy allows EventBridge to publish events to the log group
data "aws_iam_policy_document" "eventbridge_log_policy" {
statement {
actions = [
"logs:*",
]
resources = [
"${aws_cloudwatch_log_group.logs.arn}:*"
]
principals {
identifiers = ["events.amazonaws.com", "delivery.logs.amazonaws.com"]
type = "Service"
}
principals {
type = "AWS"
identifiers = [var.aws_account_id]
}
}
}
resource "aws_cloudwatch_log_resource_policy" "logs" {
policy_document = data.aws_iam_policy_document.eventbridge_log_policy.json
policy_name = "log-publishing-policy"
}
#Creates event target for the event rule to push matching events to the log group.
resource "aws_cloudwatch_event_target" "eventrule" {
rule = aws_cloudwatch_event_rule.eventrule.name
event_bus_name = aws_cloudwatch_event_bus.messenger.name
arn = aws_cloudwatch_log_group.logs.arn
}Considerations:
- We considered using S3 notifications instead of sending custom events through our bash scripts. We went the custom event route as we wanted to include specific information about the Hadoop source and AWS glue tables that our consuming accounts would find useful instead of the generic S3 event that AWS provides.
- Tools like airflow/ prefect etc weren’t used in the Distcp to central AWS account process as the Hadoop team and AWS central data account teams are different and their processes are required to be decoupled. We also needed a method to notify the consuming data accounts that their data has been updated. This solution satisfies those requirements.
- The “source” for all the custom events is the same and the central data account sends all the events to the consumer accounts. It’s up to the consumers to tailor their EventBridge Rules to the specific datasets they’re interested in. This allows the architecture to be more scalable and maintainable as the central data account doesn’t have to write custom code for each consuming account and it makes onboarding new consumers easier since datasets used and requirements are constantly changing.
- We are using a Custom Event Buses in both the central data and consuming accounts. We opted not to use the default event bus to receive the events because according to AWS best practices the default bus should be kept localized to your account since all the events from your AWS services flow to this event bus. This architecture also requires the consuming accounts to give the central data account access to their event bus. Doing this on the default event bus poses a security risk.