







Data Modeling for Developers
An Introduction to Data Modeling and Why it Matters for Development Teams

Data modeling is a critical yet often underrated skill in technology development and within development teams. This article aims to teach you the basics of it and why it is important. This article will introduce you to the concept of a data model, how to create one in a business setting, and some tools you should investigate for creating them collaboratively. Additionally, I will cover some concepts from traditional data modeling you might want to explore, and I will briefly discuss how to incorporate unstructured data into your models. I don’t think there is only one right way to model data, but knowing the concepts can help you think intelligently about how the data in your systems ties together and therefore build better systems. This can help you understand what pieces need to come from your application, which come from other databases or APIs, and which originate in some crusty old Access database on a shared drive somewhere.
Why Should You Model Data?
Many times in my career I have joined development teams at large, sophisticated organizations with an existing product only to find nebulous requirements and low team understanding of what the system they have designed does, where it gets its data from, and what data this system should be producing. Data modeling can help solve this problem as a sort of lean requirements document and communication tool, making sure there is alignment on what the product is aiming to achieve with guidelines for how to achieve it. It can serve as a constant resource for teammates to understand the whole picture even if they often work on smaller parts of the application. Completing this activity early in the development process is most useful, but all is not lost if it happens farther down the road.
What is a Data Model?
A data model is a visual representation of an information system and a communication tool for designing systems of all levels of complexity. Traditionally data models are only used for representing structured data, but I have some techniques for modeling semi-structured and unstructured data that I will share with you later in this article.
Data can be modeled based on the level of detail you want to provide. There are typically three levels of detail we work with: conceptual, logical, and physical models. Conceptual models show all the concepts for the product and how they relate to each other whereas logical models pay more attention to the specific attributes that exist within those concepts and how they relate to each other.
Physical models then take logical models one step further by showing how the implementation will occur with the specific data types, nuances, and optimizations of the database system considered in the models. For example, most databases will use a UUID (Universally Unique IDentifier) to uniquely identify information whereas GUIDs (Globally Unique IDentifiers) are similar but tend to be used in Microsoft-specific databases and systems. This is the sort of distinction you make when converting a logical model to a physical model. However, I will focus on conceptual and logical models here.
For fun and because I love ice cream, I will use the example of creating an app for managing orders and inventory for an ice cream shop to demonstrate these concepts.
When creating the conceptual model, you want to get all the ideas out there for what things are relevant to this ice cream app. Many questions will come up in this exercise, and I find it quite useful to work on the conceptual model with the business to get answers to these questions faster. Some questions that make you feel like you do not understand the business will likely come up: do we allow delivery of our ice cream? Who ARE all our suppliers, and how DO we add new ones? It can help to have an experienced facilitator for these conversations, but it is not critical.
Below is an example of the high-level concepts you might have produced doing this exercise. When we have done this in workshops and with business groups, there are always extra words that are volunteered that don’t really fit the high-level conceptual model. BUT that does not mean they are not useful. Those words and concepts will go into how we design the logical model, which adds attributes to these high-level concepts.
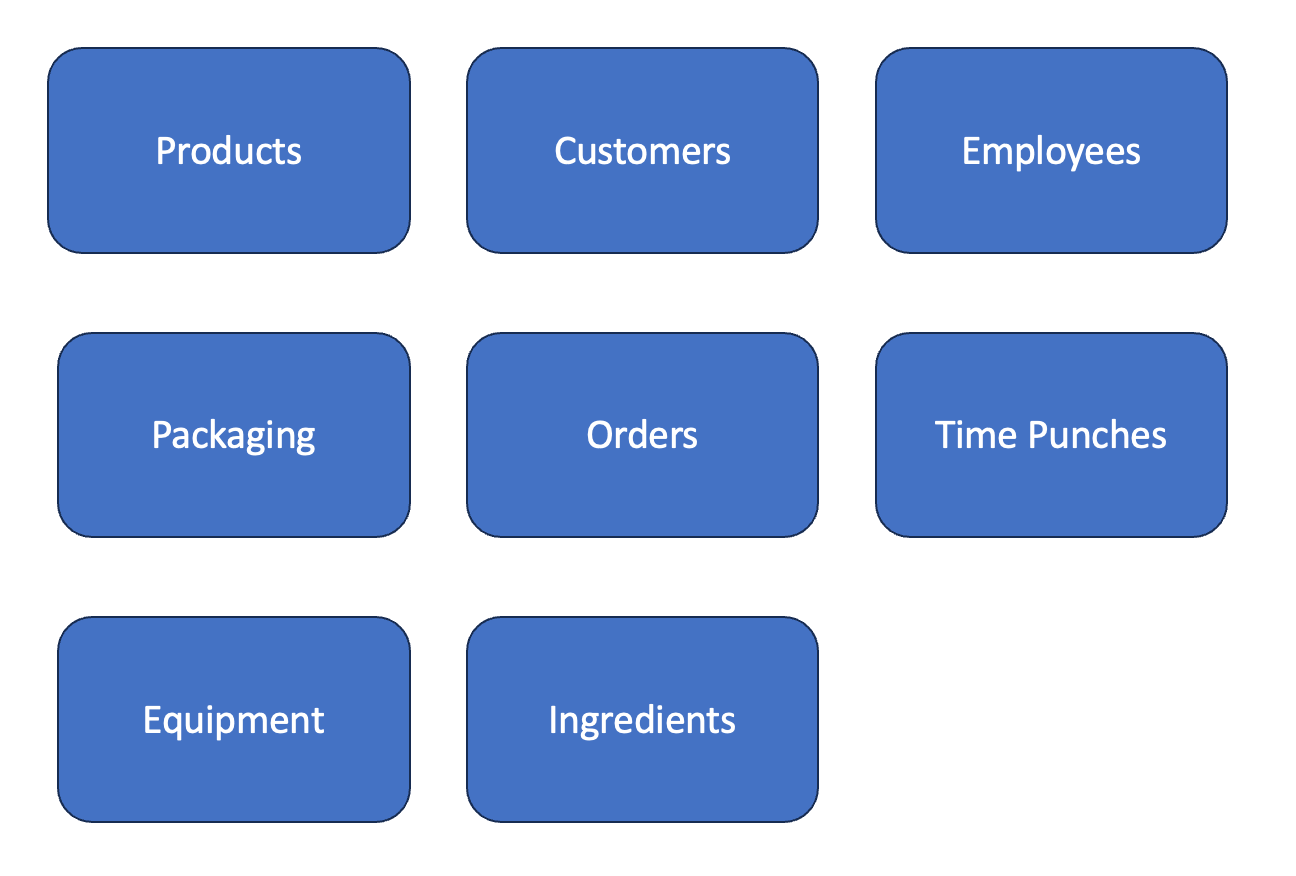
Once we have gotten all the high-level concepts out there, we want to figure out how they relate to each other. There are a handful of techniques for doing this, but I like to add verbs to the connections between the high-level concepts. One example of that finished conceptual model is below.
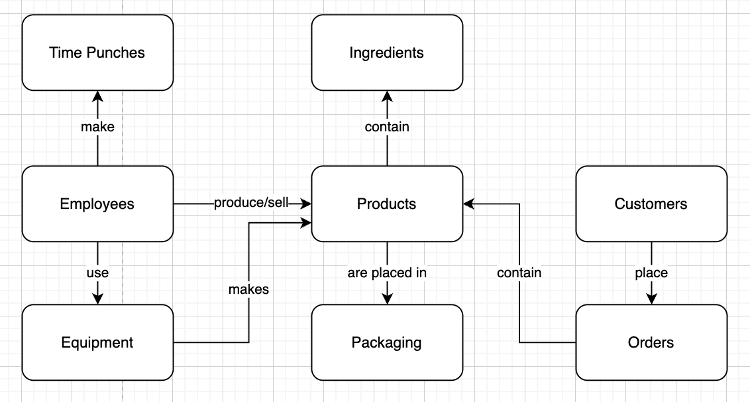
Finally, once you have a conceptual model that incorporates all the key parts of your product, you have two important steps left to create your logical model before you iterate on the resulting model.
- Adding attributes to your high-level concepts, which now become tables. The attributes you assign become the columns.
- Adding relationships between the tables.
Table relationships
Relationships between tables are often expressed in crows-foot notation, and this is the part many developers I have worked with struggled to get right on the first attempt. So, if you are confused, know you are not alone. It takes time and practice to really master.
The symbols below are used to show how tables relate to each other. You want to specify if, for example, a product can contain zero, one, or many ingredients. Most of the lines you have in your conceptual model should be replaced with these symbols which will inform many things about how you implement your final product such as database constraints.

Attribute selection
Adding attributes is another useful activity to perform with the business representatives. Getting all the ideas out for what data needs to be collected, incorporated, or displayed is quite powerful. Below is an example of what part of the conceptual model might look like as a logical model:
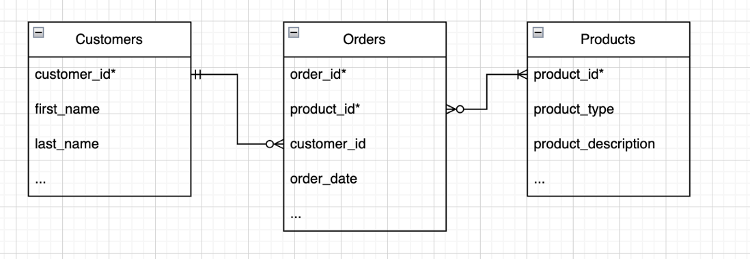
There are four useful statements that this model shows.
- Customers make zero to many orders. Based on our business logic we might let people be “customers” before making a purchase. Maybe it’s a necessary condition that they first sign up and only then can make a purchase.
- Orders are made by one and only one customer. Our business team decided they do not want to split checks.
- Each order contains one or many products.
- Each product is in zero to many orders. When we add new products, they will not be in any orders right away. This crow’s foot representation accounts for that.
Exercise
A great exercise for you is to complete the model I started. There can be a few answers depending on how you think the business logic would work here.
Next steps
After this exercise, there can be a handful of next steps. The team can then suss out if this data already exists in the ecosystem and should have a separate source of truth or if it should originate in the application we are designing. Determining this may necessitate modifications to the model structure. If you initially envision data this application owns and data another application owns in the same table it usually makes sense to split that apart for ease of updating asynchronously.
Once you have that complete version of the model, it is time to iterate!
Some additional questions to think about as you iterate through your design:
- Do you need to store all updates or just the most recent true value?
- Do you have any duplicates where your system will need to update multiple tables at once? If so, you will almost always want to clean this up.
- Do you need to show analytical results in the app? Do the results need to be always up-to-date or can you tolerate some latency?
- Do you have any many-to-many relationships between your tables? How can you make that easier for the system to join?
- Are all your primary and foreign keys numerical?
Tools for Creating Data Models
I prefer draw.io, Lucid Chart, or Miro because they have clean UIs, and they let you focus on just the concepts, their attributes, and the relationship between the concepts, which become tables or documents. So many other tools for enterprise are bogged down with too much planning, process, and irrelevant detail that they are both boring and cumbersome to use.
Traditional Data Modeling Techniques
Once you have created a logical model using the above approach you might want to take some ideas from traditional data modeling schools of thought. You can still get a lot of business value out of data modeling without this, but the concepts in this section help you consider various nuances that will help your system design. Normalization and dimensional modeling are the main concepts I find useful to incorporate into aspects of the applications I have built.
Normalization
Normalization is a useful concept that helps us think about how to handle duplicate information in tables and rows, thus improving data integrity. Data warehouse modeling using normalization (or normal forms) was proposed by Bill Inmon, who is widely considered to be the father of data warehousing. There is some momentum to move away from central data warehouses due in part to the trouble of validating the accuracy of information across disparate systems. To me, this happens because of the lack of clear ownership you get with a centralized view of all company data. BUT understanding normalization and where we can and cannot have duplicate information in our tables is critical to a clean and dry design in smaller data systems, too; this type of design promotes cheaper and more efficient data storage.
Dimensional Modeling
Dimensional modeling is a powerful technique developed by Ralph Kimball in the 1990s. It seeks to design data analysis systems using facts and dimensions where dimension tables provide context such as who ordered the ice cream, what they ordered, when they ordered it, and where they ordered it from. Fact tables condense the data into useful aggregates that summarize the key analytical takeaways such as how much ice cream we sold, and how much our packaging and ingredients cost us over that same period. This fact could have all the details that allow us to extrapolate if our business is profitable or not.
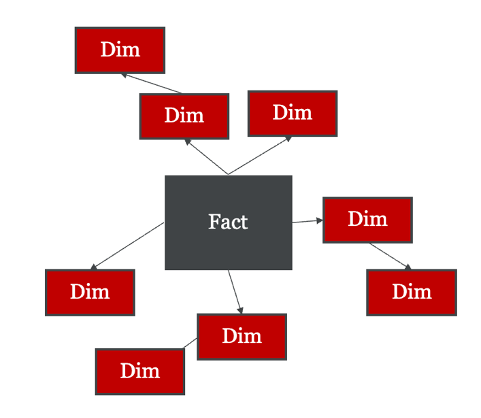
The level of granularity you are working with and the grain you want to have in each step of the application is extremely important. For example, level of granularity is important in our ice cream application to understand if we want to record data at the order level or at the bucket of ice cream sold level (or perhaps both). Whenever I design and build new systems, I am constantly asking myself if we are operating at the right grain or granularity of information.
Some Thoughts on Modeling with noSQL and Combined SQL-NoSQL Systems
My general thought on modeling data that is less structured and therefore probably more likely to use a NoSQL database is as long as there is some identifier and some rules for what this data will look like, you can use the same techniques discussed above. Below is an example of how I might incorporate a Document database where all my recipes are kept in a document database.
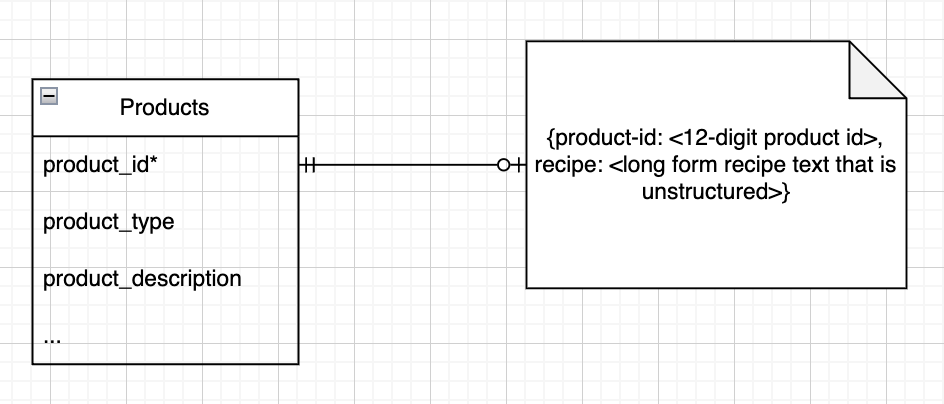
The above shows that a product has zero or one recipe, and each recipe is for one and only one product.
Conclusion
Data modeling can save your team a ton of time and rework because it connects the business concepts to what needs to be engineered. The team can then focus on how to build that solution with a solid understanding of what and why. In a time when Agile is so present and some organizations tout requirements gathering as waterfall-esque, activities like this can be profoundly useful; they force us to have the right kinds of conversations and get the ideas relevant to the product on the table for everyone to look at from many different angles.
Please reach out if you have questions or ideas about how to do any of this productively or have any related ideas you would like to talk about.