







DBT and Databricks part 3: Loading noSQL data (from MongoDB) into Databricks

This series of blog posts will illustrate how to use DBT with Azure Databricks: set up a connection profile, work with python models, and copy noSQL data into Databricks(from MongoDB). In the third part, we will talk about one specific example of how to load noSQL data into Databricks(originally coming from MongoDB).
Task:
We have an upstream process exporting all new data from MongoDB into the Azure blob storage. We need to load this data into Databricks and upsert it into the existing table.
Complications:
- Data is exported to JSON files on a regular basis(once in 6 hours) and we need to set up a process also running on schedule (once a day) to read and process only new JSON files.
- JSON files coming from MongoDB (NoSQL database) might have different schemas, some columns(key:value pairs) can be present/absent across files.
- Code needs to be added to the existing workflow based on DBT, so this needs to be implemented with DBT.
Solution
See Part 1 on how to configure DBT Databricks profile and Part 2 on DBT, Databricks, and python models.
We will use the Autoloader feature of Databricks, it has a checkpointing mechanism and allows us to read only new (not processes before) files.
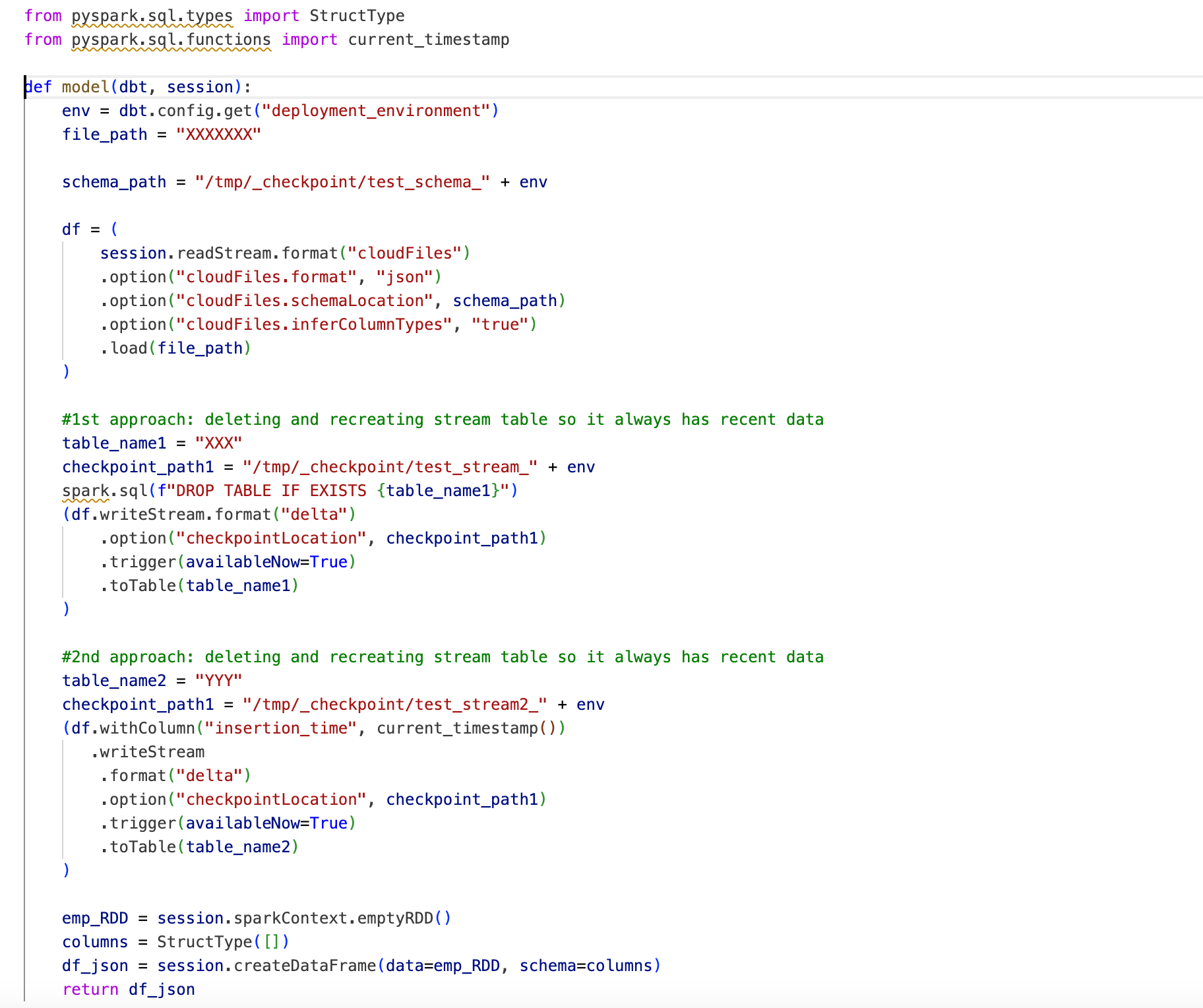
Reading data using Autoloader:

.format("cloudFiles") and .option("cloudFiles.format", "json")options indicate that we are using Autoloader and the reading format is json.
.option("cloudFiles.schemaLocation", schema_path) – is a location where it will internally store information about auto-detected schema.
.option("cloudFiles.inferColumnTypes", "true") – it is a nice option for Autoloader to try to autodetect column types (if we don’t specify this option – everything will be set to String type).
Then we need to write this data into the output table:

.outputMode("append") – this is the default option to append data to the table – we can omit it.
.option("checkpointLocation", checkpoint_path) – specifying where Autoloader stores its checkpoints to keep track of files it processed before.
.trigger(availableNow=True) – means we will run this in batch mode and not in streaming mode, it will write only data available currently and stop.
.option("mergeSchema", "true") – merge schema is a very cool option: when a new portion of data is read from recent JSON files and if there are any new columns(key:value pairs) in this data – schemas of existing table and new JSON data will be merged, new columns will be added to the table with Null values for all previous data and new data will be appended to the bottom.
But there is one catch here: the process will fail with an error when new columns are added and will need to be restarted. (In our case we run DBT with Airflow and it is configured to auto-restart failed tasks). This is expected behavior and data is not lost.

Now thinking of outputMode("append") option – maybe is not what we exactly want? We actually want to keep only the latest batch of data in the output table and then upsert it into another table. There are a couple possible solutions here:
- We can overwrite the output table instead of appending to it (
outputMode("complete")).
2. We can leave outputMode("append") and continue appending to the output table but add a separate column with a timestamp to indicate when the record was added to be able to take only the latest records to the next step(upsert).
Trying approach1: looks like outputMode("complete") is not supported to work with Autoloader :

So the simplest solution if we want to overwrite data is to drop the table and re-create it before writing:
spark.sql(f"DROP TABLE IF EXISTS {table_name}")
And we don’t need the option .option("mergeSchema", "true") in this case, since the output table will not exist. However, it will still throw an error on new columns (and needs to be restarted) since schema information is still preserved by Autoloader.
Or, alternatively, we can use the approach2: we continue to append data to the output table will add the timestamp column to be able to filter out only the most recent records:

Note: We can also combine two approaches together and create two resulting tables from the same stream – but in this case, we need to use new checkpoints for the second table.
And the last bit here is to convert everything to DBT. So we wrap this code in DBT model standard and immediately hit another issue: DBT has to return a dataframe, but can’t return a Streaming dataframe. Streaming dataframe will be successfully written to the output table but can’t be used in the return() statement of the model.
To make DBT happy we can just make dummy data and return it.
The full code is here:
Now we can read this data and upsert into the existing table using incremental DBT models(Check Part 2 for information on how to configure python incremental models).
Happy Coding! 🙂