

Introduction
After exploring how vector databases work and trying the AWS OpenSearch vector database in this blog post, the goal of this article is to experiment with a similar product from Databricks – Mosaic AI Vector Search. We will create a new Vector Search endpoint and index, load the toy dataset, try to perform similarity and hybrid searches and rebuild the index using new data. We will be using this reference to experiment with the Python package databricks-vectorsearch.
Mosaic AI Vector Search
Mosaic AI Vector Search is a vector database within the Databricks platform that enhances search capabilities by combining vector embeddings with traditional search methods.
Additional feature of Mosaic AI Vector Search hybrid search (for now, Sep 2024, in public preview).
Hybrid search in vector search databases refers to a search technique that combines traditional keyword-based search with vector-based semantic search to provide more accurate and relevant results. It leverages both the precision of keyword matching and the contextual understanding of vector embeddings.
Here’s how it works:
Keyword-based Search: This component uses traditional search techniques, such as inverted indices, to find documents or records that contain exact keyword matches. It’s highly efficient for specific terms or phrases.
Vector-based Search: This component converts data (text, images, etc.) into high-dimensional vectors and searches for items with similar semantic meanings, even if the exact words or terms don’t match.
By merging these two approaches, hybrid search ensures that results are both contextually relevant and highly precise. It addresses the limitations of each method – vector search can miss exact keyword matches, while keyword search can overlook semantic connections. Hybrid search is especially valuable for applications involving natural language processing (NLP), recommendation systems, and large, unstructured datasets.
There are different options for loading data into Mosaic AI Vector Search and calculating embeddings as described here.
We will be using Option1:
- using an input dataset to create a new Delta table,
- building a Vector Search index based on this table( using one of the Databricks foundation models to calculate embeddings),
- when the underlying Delta table is updated – rebuilding the index to add new data (it can be done in a triggered or continuous way, see below).
Step-by-step
We will be using a toy dataset with movie plots, this dataset has information about 20 movies: id, title, genre and plot, it can be downloaded from here.
- Create a new compute resource: spark cluster with the Python library databricks-vectorsearch installed (I have used 15.4 LTS (includes Apache Spark 3.5.0, Scala 2.12) for testing).
- Create a new notebook, attach it to the newly created cluster and import vectorsearch client:
from databricks.vector_search.client import VectorSearchClient
- Define some constants:
CATLOG_NAME = ""
SCHEMA_NAME = "vectorsearch"
VS_ENDPOINT_NAME = "vector_search_endpoint"
VS_MODEL_NAME = "databricks-bge-large-en"
TABLE_NAME = "movies"
INDEX_NAME = "moviesindex"
Have chosen “databricks-bge-large-en” model for embeddings from the list of of current Databricks foundation models.
- Create a VectorSearchClient instance and set up a Databricks Vector Search Endpoint if it does not exist.
#create VectorSearch client
vsclient = VectorSearchClient(disable_notice=True)
#create VectorSearch endpoint if it does not exist
try:
vsclient.get_endpoint(name=VS_ENDPOINT_NAME)
print("VectorSearch endpoint already exists.")
except Exception as e:
if ('status_code 404' in e.args[0]): #endpoint does not exist
#vsclient.create_endpoint_and_wait(name=VS_ENDPOINT_NAME)
vsclient.create_endpoint(name=VS_ENDPOINT_NAME)
print("VectorSearch endpoint is created.")
else:
print(e)
According to the documentation, function create_endpoint_and_wait() should be able to create the endpoint and wait for it to be online, but I was having issues running it(Error message: “KeyError: endpoints..”).
So using the regular create_endpoint() function, it will finish running the cell immediately but we need to watch the actual endpoint to become online: on Databricks UI go to Compute -> Vector Search. Our endpoint will be in the provisioning state for several minutes:
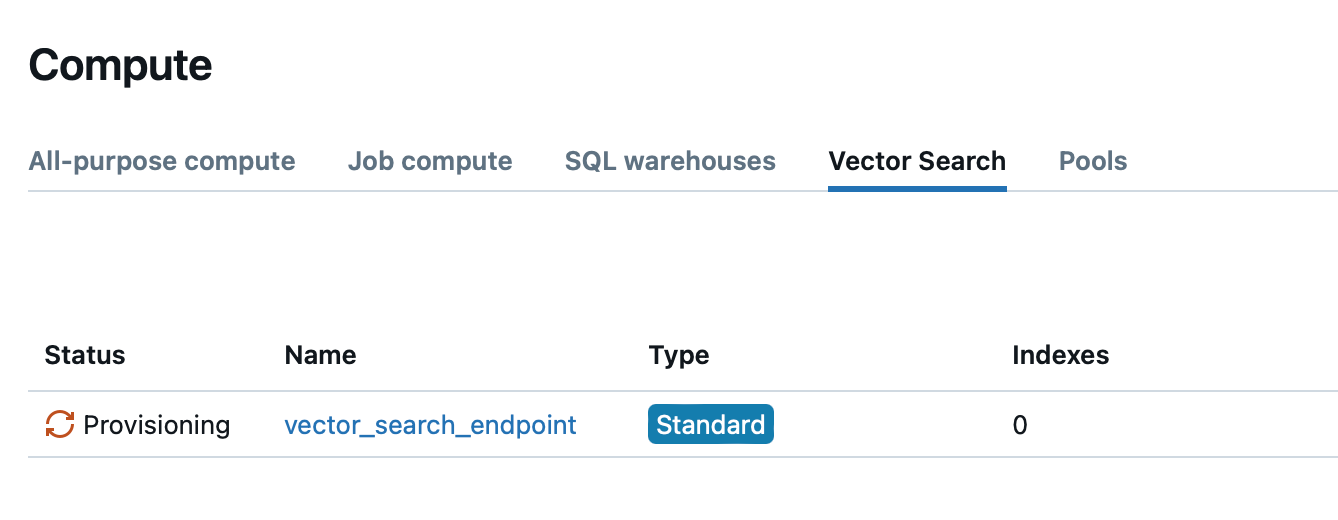
Once it gets online, we can move on to the next cell in the notebook:
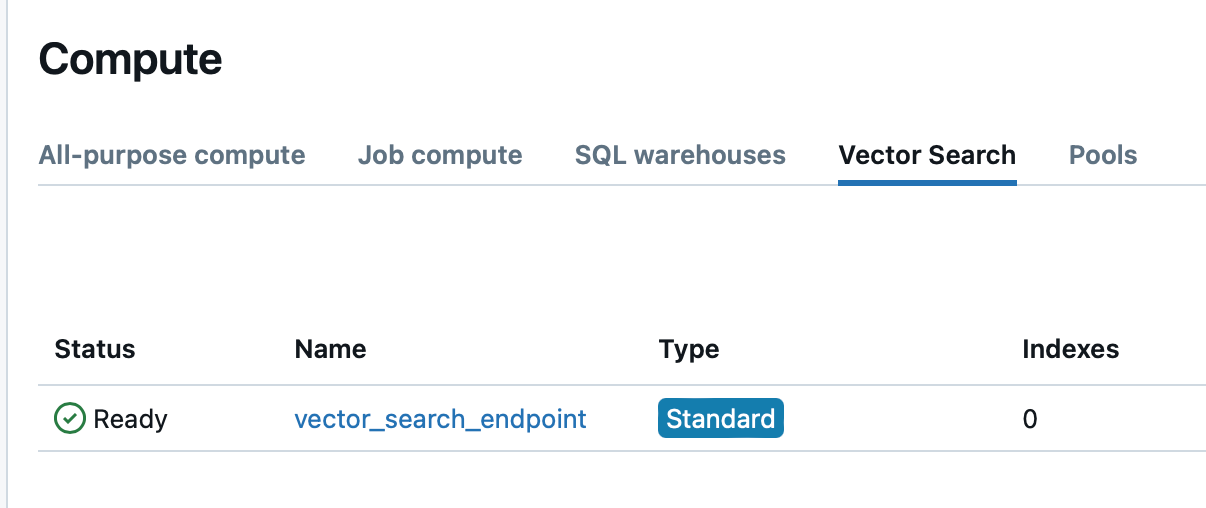
- Reading our toy dataset, loading it into the Delta table and enabling ChangeDataFeed (need to have this setting on for the Vector Search index):
df = spark.read.csv("s3:///data/movie_plots.csv", header=True)
#display(df)
#load data into delta table and enable ChangeDataFeed
(df
.write
.format('delta')
.mode('overwrite')
.option('overwriteSchema','true')
.option("delta.enableChangeDataFeed", "true")
.saveAsTable(f"{CATLOG_NAME}.{SCHEMA_NAME}.{TABLE_NAME}")
)
- Creating Vector Search index:
#create vectorsearch index
index = vsclient.create_delta_sync_index_and_wait(
endpoint_name=VS_ENDPOINT_NAME,
source_table_name=f"{CATLOG_NAME}.{SCHEMA_NAME}.{TABLE_NAME}",
index_name=f"{CATLOG_NAME}.{SCHEMA_NAME}.{INDEX_NAME}",
pipeline_type='TRIGGERED',
primary_key="movie_id",
embedding_source_column="plot",
embedding_model_endpoint_name=VS_MODEL_NAME
)
In this case function create_delta_sync_index_and_wait() works perfectly – the cell keeps running until the index is built and becomes ready. We can watch it building on the Databricks UI: Compute->Vector Search -> . There are 0 rows indexed at the beginning:
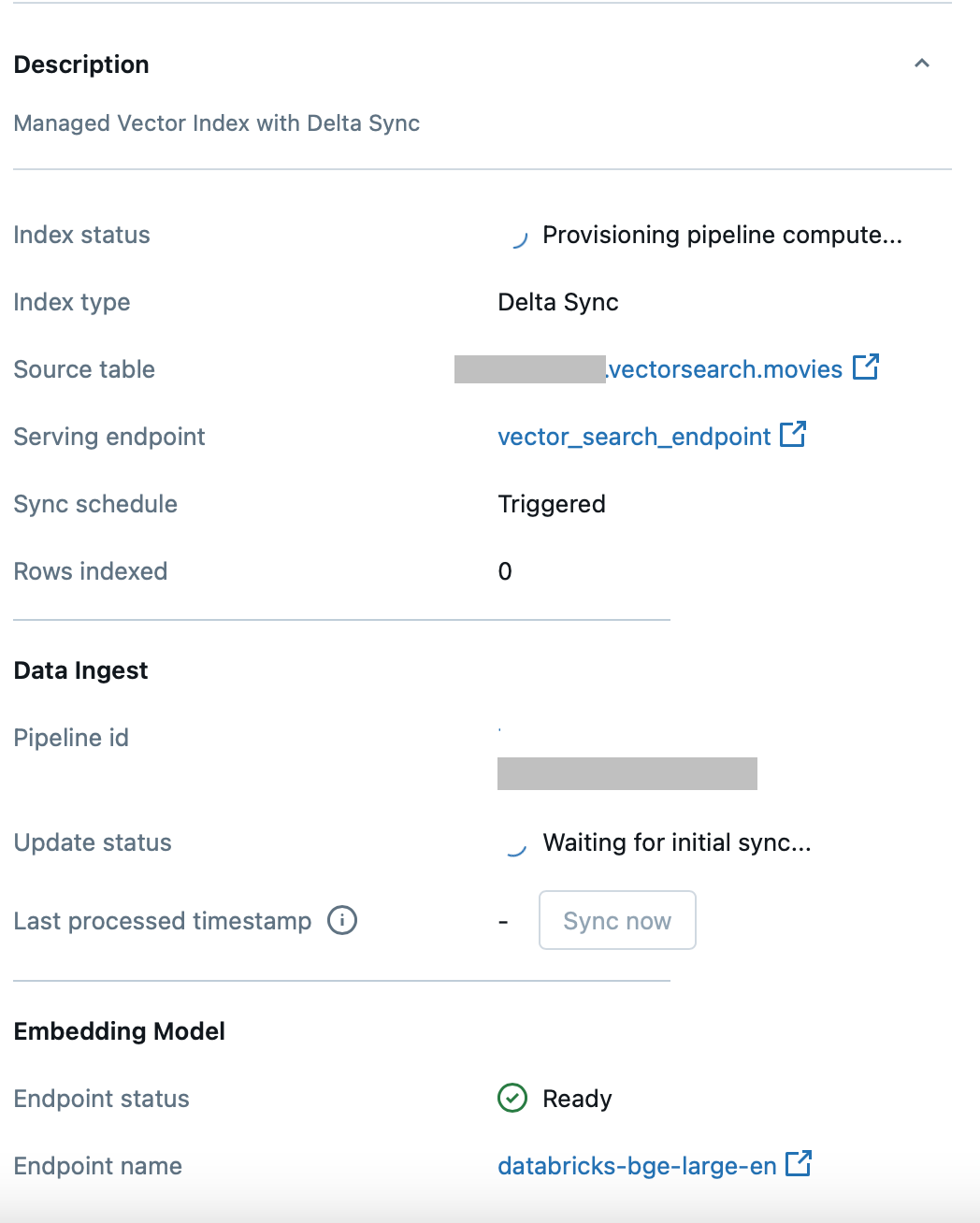
After several minutes, it indexes 20 rows and becomes online:
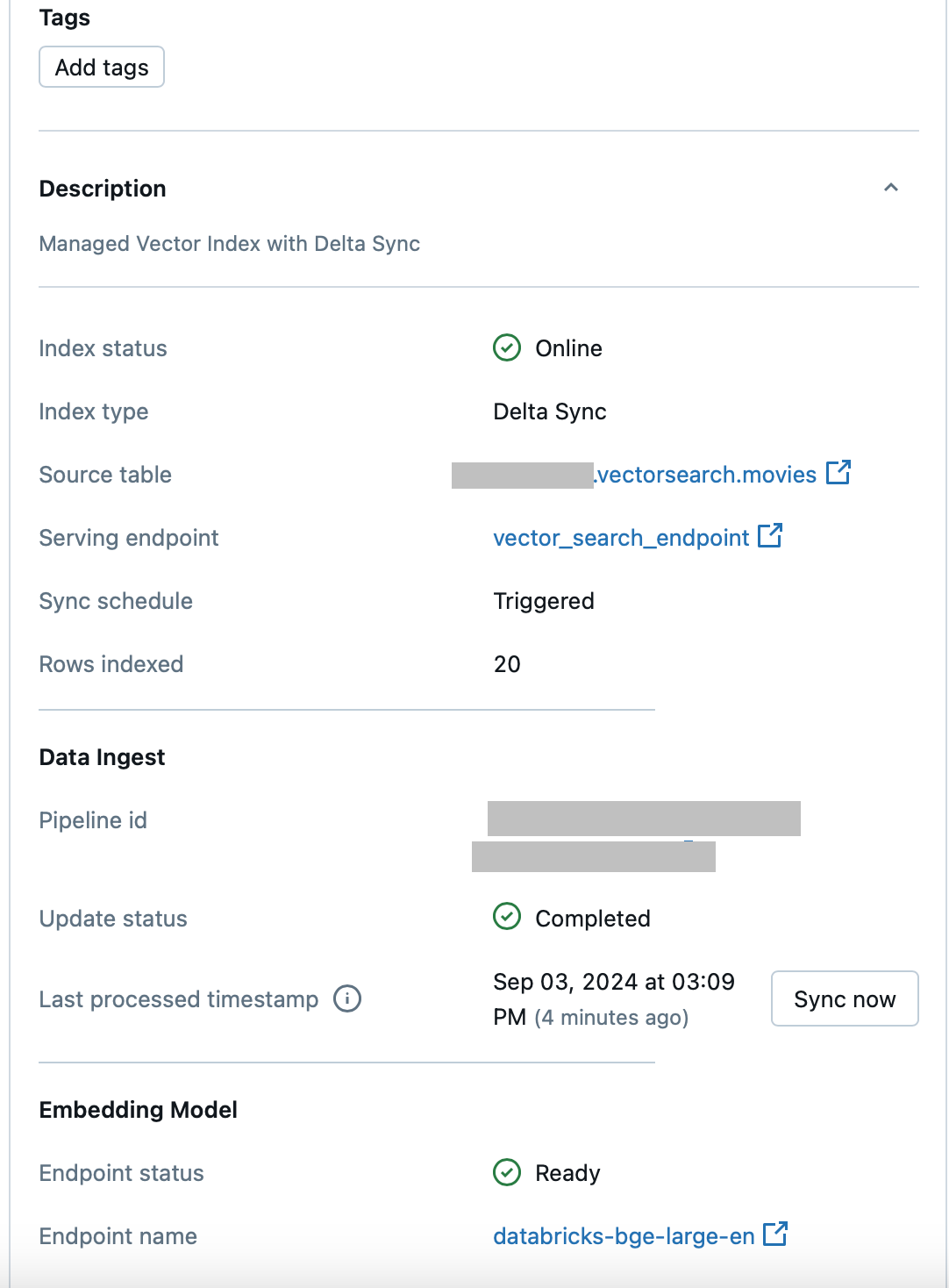
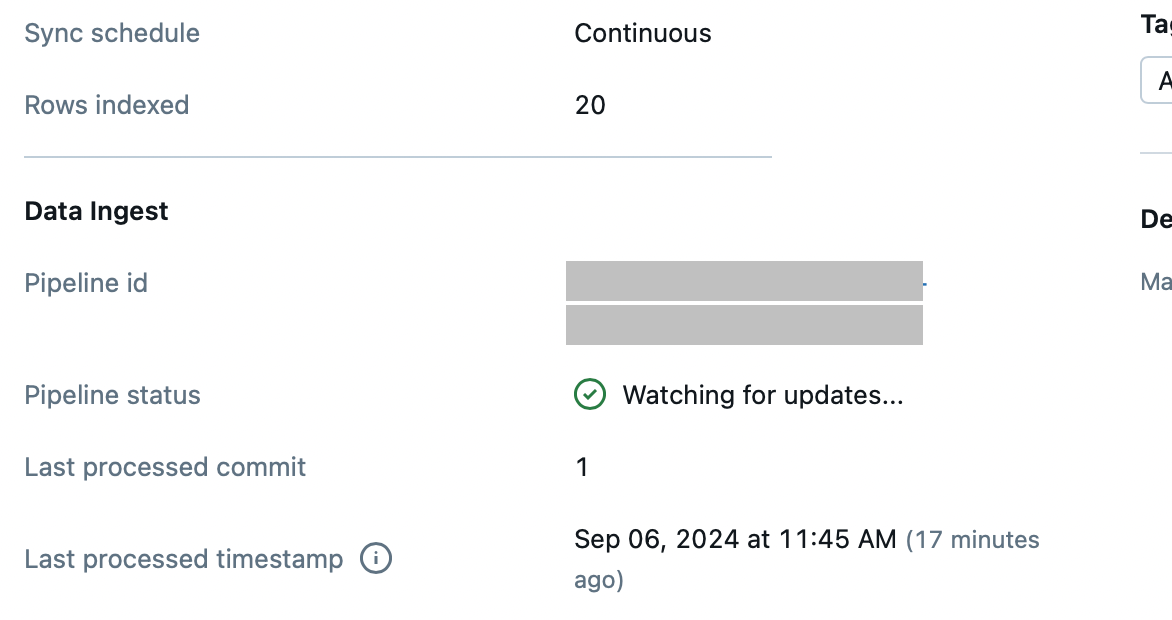
Note: instead of pipeline_type=’TRIGGERED’ we can use pipeline_type=’CONTINUOUS’ and then the index will be rebuilt automatically when the underlying Delta table is changed, don’t need to call index.sync(). In this case, it takes a longer time to create the index initially (took 12 mins for me ) and when it is created, you can see on the UI (note Sync Schedule and Update Status):
- Now we can define a helper function for displaying the results and test the similarity search:
#helper function to display search results
def display_search_results(results):
rows = results['result']['data_array']
for (movie_id, genre, plot, title, score) in rows:
if len(plot) > 32:
plot = plot[0:32] + "..."
print(f"id: {movie_id} title: {title} genre '{genre}' plot '{plot}' score: {score}")
#testing similarity search
results = index.similarity_search(
query_text="A group of friends embark on an epic adventure to destroy a powerful ring.",
columns=["movie_id", "genre","plot","title"],
num_results=3,
)
display_search_results(results)
The output:
id: 6 title: The Lord of the Rings: The Return of the King genre 'Adventure' plot 'Gandalf and Aragorn lead the Wor...' score: 0.59288234
id: 20 title: Interstellar genre 'Sci-Fi' plot 'A team of explorers travel throu...' score: 0.5451615
id: 12 title: The Empire Strikes Back genre 'Action' plot 'After the Rebels are brutally ov...' score: 0.5049474
Trying similarity search with filtering:
results = index.similarity_search(
query_text="A group of friends embark on an epic adventure to destroy a powerful ring.",
columns=["movie_id", "genre","plot","title"],
num_results=3,
filters={"genre NOT": "Adventure"}
)
display_search_results(results)
id: 20 title: Interstellar genre 'Sci-Fi' plot 'A team of explorers travel throu...' score: 0.5451615
id: 12 title: The Empire Strikes Back genre 'Action' plot 'After the Rebels are brutally ov...' score: 0.5049474
id: 17 title: Saving Private Ryan genre 'War' plot 'Following the Normandy Landings,...' score: 0.4915407
Hybrid search:
results = index.similarity_search(
query_text="A group of friends embark on an epic adventure to destroy a powerful ring.",
columns=["movie_id", "genre","plot","title"],
num_results=3,
query_type="hybrid"
)
display_search_results(results)
id: 6 title: The Lord of the Rings: The Return of the King genre 'Adventure' plot 'Gandalf and Aragorn lead the Wor...' score: 0.9765625
id: 17 title: Saving Private Ryan genre 'War' plot 'Following the Normandy Landings,...' score: 0.9606894841269842
id: 16 title: The Usual Suspects genre 'Mystery' plot 'A sole survivor tells of the twi...' score: 0.9485294117647058
Note: how high the scores are with the hybrid search!
- Next step, let’s try to add a new row to the table, we insert the Peter Pan movie:
#add new data to the delta table
spark.sql(f"""INSERT INTO {CATLOG_NAME}.{SCHEMA_NAME}.{TABLE_NAME} (movie_id, title, genre, plot) VALUES (21, 'Peter Pan','Kids', 'Peter Pan, a boy who never grows up, takes the children Wendy, John, and Michael to magical Neverland, where Wendy mothers the Lost Boys.') """)
- Now if we try to search for it – it will not work:
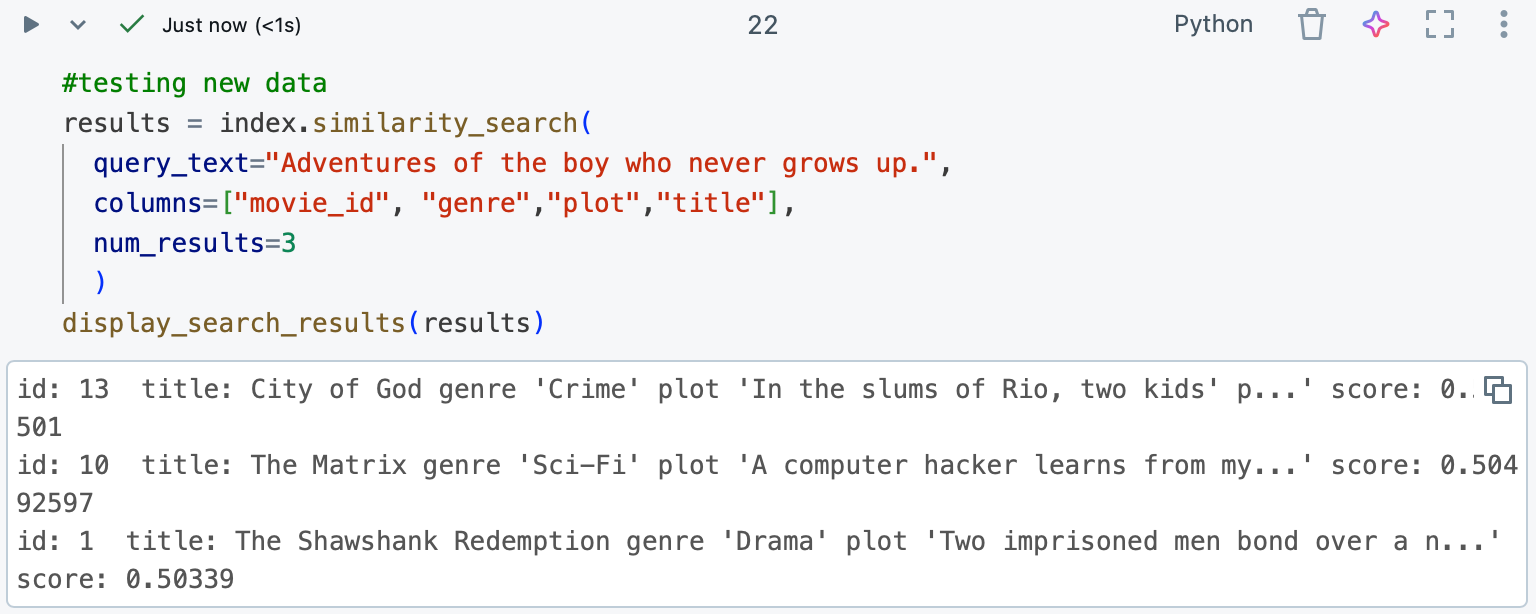
Why it is not working?
- We need to sync the Vector Search Index first (since we have specified pipeline_type=’TRIGGERED’, with continuous type it syncs automatically):
#it takes a while to rebuild the index
index.sync()
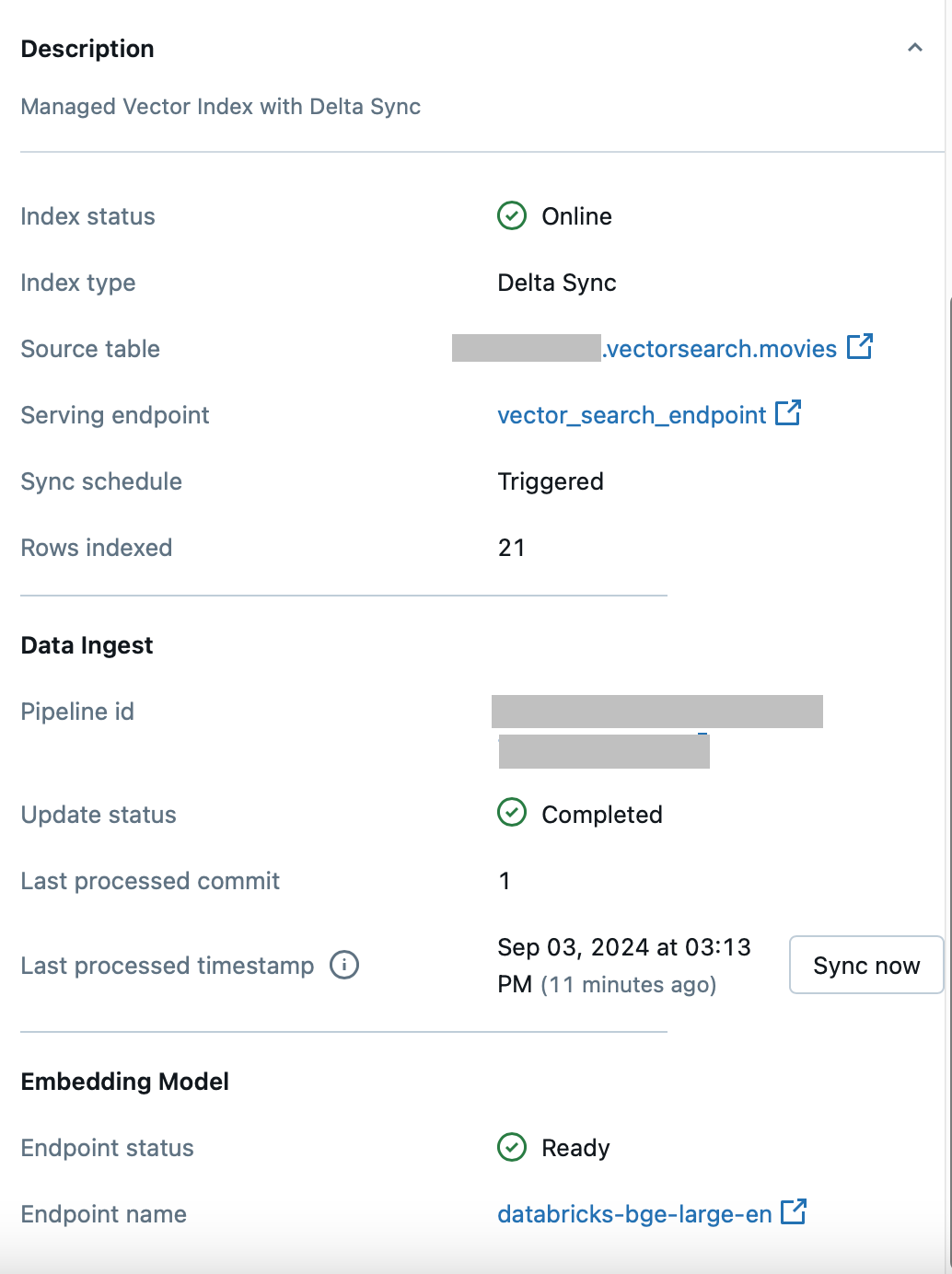
After checking the index on the UI after several minutes we can see that there are 21 indexed rows now:
- If we query the index now – the results look correct:
#testing new data
results = index.similarity_search(
query_text="Adventures of the boy who never grows up.",
columns=["movie_id", "genre","plot","title"],
num_results=3
)
display_search_results(results)
id: 21 title: Peter Pan genre 'Kids' plot 'Peter Pan, a boy who never grows...' score: 0.591169
id: 13 title: City of God genre 'Crime' plot 'In the slums of Rio, two kids' p...' score: 0.518501
id: 10 title: The Matrix genre 'Sci-Fi' plot 'A computer hacker learns from my...' score: 0.50492597
- Deleting index and table:
#delete vectorsearch index
vsclient.delete_index(endpoint_name=VS_ENDPOINT_NAME, index_name=f"{CATLOG_NAME}.{SCHEMA_NAME}.{INDEX_NAME}")
#delete unity catalog table
spark.sql(f"""DROP TABLE {CATLOG_NAME}.{SCHEMA_NAME}.{TABLE_NAME}""")
Conclusion
We have experimented with the Databricks Mosaic AI Vector Search database, created endpoint, and index, tried similarity and hybrid searches as well added new data to the index. Hope this basic notebook can give a good introduction and foundation for Databricks Mosaic AI Vector Search database. Let me know if you have any questions or suggestions, happy coding!