







External Knowledge Base for LLMs: Leveraging Retrieval Augmented Generation Framework with AWS…

Introduction
In the realm of artificial intelligence and language models, the pursuit of enhancing their capabilities is a constant endeavor. Today, we embark on a journey to explore an innovative approach that has the potential to revolutionize the way we harness the power of AI. Picture a scenario where your language model not only excels at answering domain-specific questions with precision but also possesses the ability to sift through your organization’s confidential documents, all while effortlessly staying updated with the latest information. This is the promise of integrating an external knowledge base into your Large Language Model (LLM).
In this blog post, we delve into the vast potential of this groundbreaking approach. We’ll uncover how augmenting your LLM with external knowledge can be a game-changer in AI, and we’ll demonstrate why it stands out as a cost-effective and straightforward alternative to the conventional method of fine-tuning models with specific knowledge.
Problem Statement:
The AI Knowledge Gap: Bridging Domain-Specific Questions with LLM Models
In the world of cutting-edge AI and language models, we encounter a pressing challenge: how to enhance their performance in addressing domain-specific questions, unlocking insights from confidential company documents, and ensuring they remain current with the latest information. The problem is the inherent limitation of Large Language Models (LLMs) in offering precise, up-to-date, and domain-specific answers.
Fine-tuning these LLMs, while a common practice, presents its own set of hurdles. It demands a significant financial investment, consumes time and resources, and often yields suboptimal results. Furthermore, even after such arduous fine-tuning, these models may still fall short when confronted with highly specialized inquiries or data residing within private documents.
Compounding this issue, LLMs are typically trained on a fixed dataset, rendering them unable to adapt to the unique nuances of specific domains. This rigidity can lead to outdated responses, as these models may lack access to the most recent or real-time information.
The problem statement, therefore, revolves around the need to devise a cost-effective, easily implementable solution that equips LLMs with the ability to overcome these limitations. We must find a way to bridge the gap between the innate capabilities of LLMs and the demands of domain-specific, confidential, and dynamically evolving knowledge. This blog post addresses this challenge by introducing the concept of integrating an external knowledge base into LLMs.
Implementation
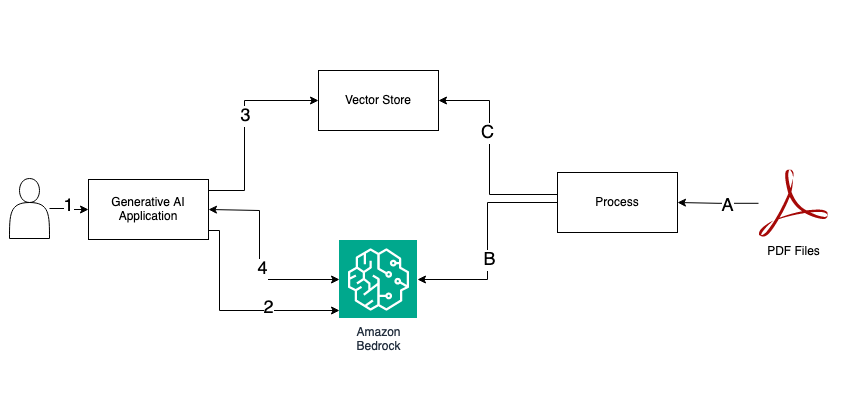
A. Process PDF files.
B. Get embedding
C. Store embedding to the vector store.
- User request: prompt
- Get embedding
- Perform Index search
- Send an updated prompt with context and get an answer
There were a few challenges with directly using pip to install the awscli, boto3, and botocore Python packages. To resolve the issue, we are downloading dependencies from the link provided in the code and installing them in the virtual Python environment.
#!/bin/sh
set -e
echo "(Re)-creating directory"
rm -rf ./dependencies
mkdir ./dependencies
cd ./dependencies
echo "Downloading dependencies"
curl -sS https://d2eo22ngex1n9g.cloudfront.net/Documentation/SDK/bedrock-python-sdk.zip > sdk.zip
echo "Unpacking dependencies"
if command -v unzip &> /dev/null
then
unzip sdk.zip && rm sdk.zip && echo "Done"
else
echo "'unzip' command not found: Trying to unzip via Python"
python -m zipfile -e sdk.zip . && rm sdk.zip && echo "Done"
fi# Make sure you ran `download-dependencies.sh` from the root of the repository first!
%pip install --no-build-isolation --quiet --force-reinstall \
../dependencies/awscli-*-py3-none-any.whl \
../dependencies/boto3-*-py3-none-any.whl \
../dependencies/botocore-*-py3-none-any.whl%pip install --quiet langchain==0.0.249 \
pypdf \
faiss-cpu \
unstructured \
pdf2image \
pdfminer-sixpThe following piece of code will read the PDF document and split it into pages for processing. We are not only converting these documents into text but also retaining the document object, which contains additional information about the document and its pages. This will later help us identify the source of the information.
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("content.pdf")
pages = loader.load_and_split()We will harness the capabilities of AWS Bedrock’s foundational model offering due to its seamless integration with various AWS services and its support for Langchain. In this demonstration, our chosen tools will be anthropic.claude-v1 for text generation and amazon.titan-embed-g1-text-02 to generate embeddings for our vector store.
# Create an instance of BedrockEmbeddings
# This class is used to interact with a Bedrock model for embeddings.
model_id = "anthropic.claude-v1"
embed_model_id = "amazon.titan-embed-g1-text-02"
titan_text_generation_config = {
"maxTokenCount":2048,
"stopSequences":[],
"temperature":0.5,
"topP":0.5
}
claude_text_generation_config = {
"max_tokens_to_sample": 100
}
if model_id == "anthropic.claude-v1":
text_generation_config = claude_text_generation_config
else:
text_generation_config = titan_text_generation_config
bedrock_embed_llm = BedrockEmbeddings(
model_id = embed_model_id
, client = boto3_bedrock
)
bedrock_llm = Bedrock(
model_id = model_id
, client = boto3_bedrock
)
bedrock_llm.model_kwargs = text_generation_configpythonWe will employ FAISS as an in-memory vector store and index to store and retrieve document embeddings. This approach works exceptionally well for a small number of documents, allowing us to read and load all the documents into the application efficiently.
# Create a VectorStore using FAISS
# VectorStore is used to store and search for vectors (embeddings) efficiently.
vectorstore = FAISS.from_documents(
documents = pages[:25]
, embedding = bedrock_embed_llm
)
# Create a VectorStoreIndexWrapper
# VectorStoreIndexWrapper is used to add an indexing layer on top of the 'vectorstore' for efficient searching.
wrapper_store = VectorStoreIndexWrapper(
vectorstore = vectorstore
)Prompt template
prompt_template = """
Use the following pieces of context to answer the question.
If the answer is not form the context then mention accordingly.
Context: {context}
Question: {question}
Answer:"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)Query
question = "Where should shareholders call with questions?"
qa = RetrievalQA.from_chain_type(
llm = bedrock_llm,
chain_type = "stuff",
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 10}),
return_source_documents = True,
chain_type_kwargs = {"prompt": PROMPT},
)
result = qa({"query": question})
print(result['result'])Additional Considerations
- Model Selection Flexibility: When implementing this approach, it’s important to note that you have a variety of foundational models to choose from within AWS Bedrock. This flexibility allows you to pick the one that best suits your specific needs. Whether it’s fine-tuning for a particular domain or accommodating different data sources, AWS Bedrock offers a range of models to fit your requirements.
- Custom Endpoint Deployment: In cases where the desired foundational model is not readily available on AWS Bedrock, AWS SageMaker comes to the rescue. It enables you to deploy custom endpoints for your chosen model, ensuring that you have the flexibility to integrate the model that aligns perfectly with your project’s goals.
- Indexing for Efficient Retrieval: Efficient information retrieval is crucial for the success of your AI-powered system. When setting up the index for your external knowledge base, consider the options available within the Amazon ecosystem. Services like Amazon OpenSearch Service, Amazon Kendra, Amazon RDS, and Amazon Aurora with pgvector can all be employed to achieve reliable and high-performance indexing. Careful selection of the right indexing service ensures that your AI system can quickly access and retrieve information, making it more responsive and effective.
- Reliability and Performance: To ensure the reliability and performance of your AI system, it’s recommended to choose an indexing service that best aligns with your project’s specific needs. Each mentioned service offers distinct advantages, so evaluate them based on your data volume, query complexity, and performance requirements. This thoughtful consideration will contribute to the overall success and responsiveness of your AI-enhanced model.
Conclusion
In conclusion, incorporating an external knowledge base into the foundational model represents a cost-effective and practical solution for improving the capabilities of our LLM. This approach enables the model to proficiently address domain-specific questions, retrieve valuable insights from the company’s private documents, and stay up-to-date with the latest facts. By choosing this approach, we can avoid the complexities and resource-intensive nature of fine-tuning the model with specific knowledge. It not only enhances the performance of LLM but also streamlines the implementation process, making it a smart choice for harnessing the power of AI in the organization.