







Harnessing the Power of Large Language Models for Knowledge Graph Creation

· The role of large language models in creating knowledge graphs from unstructured data.
· Comparison of Top Models
· Storage Platforms for Knowledge Graphs
· Practical Example: Knowledge Graph from Wikipedia Text
· Best Practices and Tips for Using Large Language Models in Knowledge Graph Creation
· Conclusion
In the vast realm of data, the ability to meaningfully connect and visualize information stands paramount. Knowledge graphs, structured representations of information, offer this capability by capturing intricate relationships between entities in a graph format. This transformative method organizes and visualizes knowledge and elucidates hidden connections between related pieces of information. Imagine a vast web where “Albert Einstein” is a prominent node, intricately connected to another node, “Theory of Relativity”, by a defining edge. This is the power and simplicity of a knowledge graph: a tool that distills vast, complex data into coherent, interrelated insights. Harnessing this power can unlock deeper understandings, innovative solutions, and informed decision-making in numerous fields.
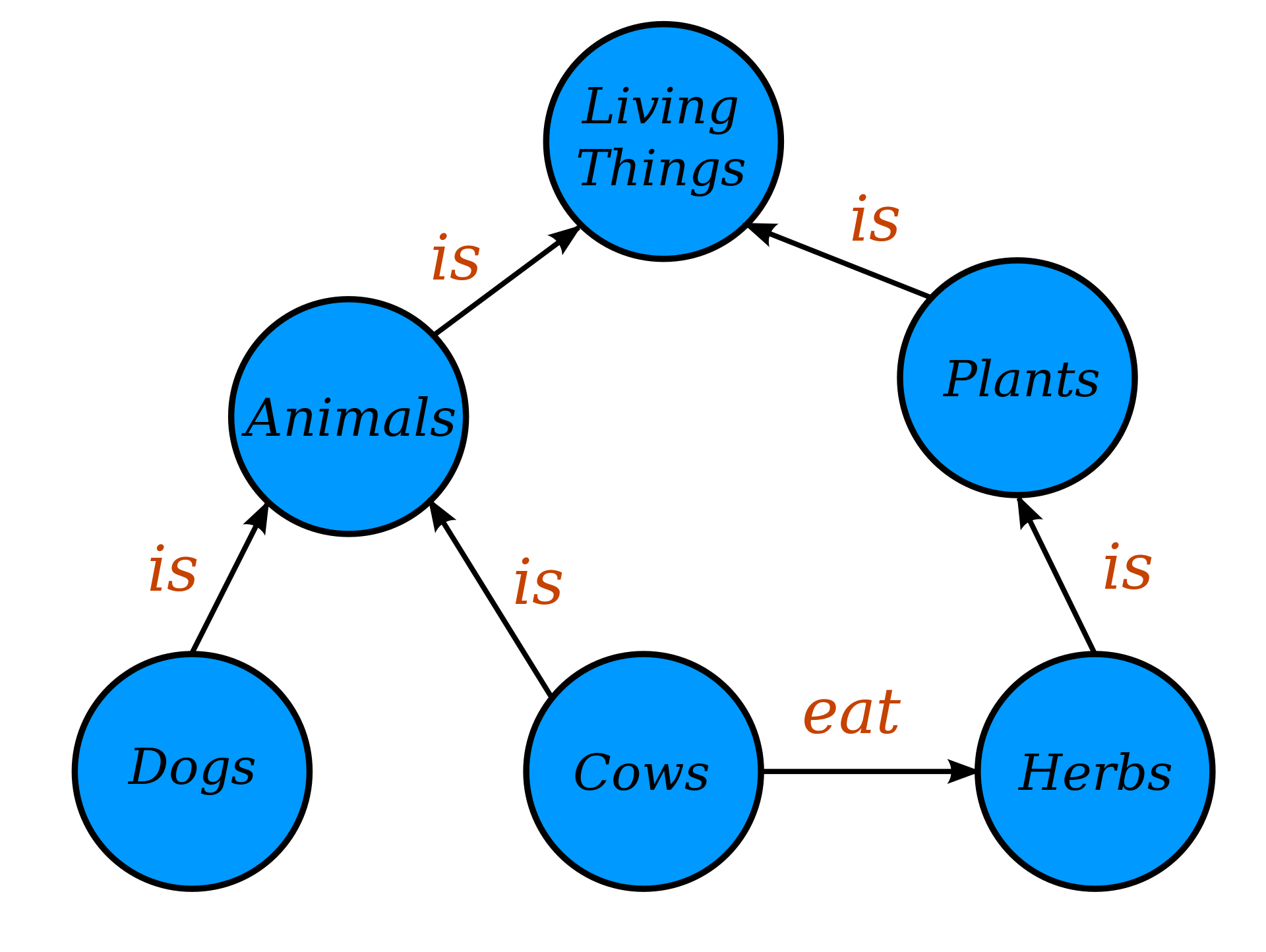
Importance of Knowledge Graphs
- Enhanced Data Connections: Knowledge graphs provide a holistic view of data, breaking down silos. Visualizing connections allows us to find patterns and relationships that might be missed in a tabular dataset.
- Semantic Search: Knowledge graphs enable semantic search capabilities, where search queries return results based on meaning and context rather than just keyword matches. For instance, searching for “apple” in a food-related knowledge graph will highlight the fruit, not the tech company.
- Personalized Recommendations: In industries like e-commerce and entertainment, knowledge graphs help provide personalized content recommendations by understanding user preferences and the connections between various items.
- Data Integrity and Verification: By linking data sources and references, knowledge graphs can validate the authenticity and accuracy of information, ensuring that users receive credible insights.
- Facilitate AI and Machine Learning: The structured nature of knowledge graphs makes them invaluable for training AI models. They offer context, which aids in better decision-making processes for algorithms.
- Knowledge Management: For organizations, knowledge graphs play a critical role in knowledge management, enabling them to capture, organize, and share institutional knowledge efficiently.
In essence, knowledge graphs have become foundational in the data-driven age. They empower businesses, researchers, and individuals to draw meaningful insights from vast amounts of data, bridging the gap between raw information and actionable knowledge.
The role of large language models in creating knowledge graphs from unstructured data.
One first needs to understand unstructured data to appreciate the role of large language models (LLMs) in knowledge graph creation. Unstructured data refers to information that doesn’t have a pre-defined data model or isn’t organized in a pre-defined manner. This encompasses a vast range of content, from text in books, articles, and web pages to audio recordings, videos, and images.
The challenge? Unstructured data, particularly textual content, holds a wealth of knowledge, but extracting meaningful relationships and entities from it is complex. This is where LLMs come into play.
Capabilities of LLMs in Knowledge Extraction
- Natural Language Understanding (NLU): LLMs possess a profound understanding of language semantics and context due to their depth and training data. This allows them to infer relationships, detect entities, and understand complex textual data at a high level of granularity.
- Entity Recognition: LLMs can identify and classify named entities within unstructured data. For instance, in a sentence like “Albert Einstein was born in Germany,” an LLM can recognize “Albert Einstein” as a person and “Germany” as a location.
- Relationship Extraction: Beyond identifying entities, LLMs can also infer relationships between them. Using the previous example, the model understands the relationship type “born in” between “Albert Einstein” and “Germany”.
- Contextual Ambiguity Resolution: LLMs can use context to resolve ambiguity in ambiguous situations where a word or phrase can have multiple meanings. For example, distinguishing between “apple” the fruit and “Apple” the company based on the surrounding text.
- Scaling Knowledge Extraction: Creating knowledge graphs from vast amounts of unstructured data is impractical. LLMs can process and extract knowledge from massive datasets at a scale unattainable by human annotators.
From Extraction to Graph Creation
Once LLMs have parsed through unstructured data, the extracted entities and their relationships can be mapped into a knowledge graph format. This automated extraction and mapping process drastically reduces the time and resources required to generate detailed and expansive knowledge graphs.
Challenges and Considerations
It is essential to understand that while LLMs are powerful, they aren’t infallible. There is a need for post-processing, validation, and potentially human-in-the-loop systems to ensure the accuracy and quality of the resulting knowledge graph. The larger and more complex the input data, the higher the potential for inconsistencies or errors in extraction.
Importance of using language models for knowledge extraction
Knowledge extraction involves gleaning structured information from unstructured sources. As our digital age continually produces vast amounts of data, automatically extracting, categorizing, and utilizing information becomes crucial. Language models (LMs) have emerged as essential tools in this domain due to the following reasons:
- Handling Voluminous Data: Manual extraction of knowledge is impractical given the scale of data generated daily. LMs can process vast datasets, extracting entities, relationships, and insights at a scale far beyond human capability.
- Deep Semantic Understanding: Advanced LMs, particularly deep learning-based models, have the ability to understand context, nuance, and semantics in text. This allows them to detect subtle relationships and inferences that simpler extraction tools might miss.
- Versatility across Domains: LMs can be applied across various domains, from scientific literature and news articles to social media posts. To enhance extraction accuracy, they can be fine-tuned or adapted to specific industries or niches.
- Continuous Learning and Adaptation: With the continuous influx of new information, the landscape of knowledge is always changing. LMs can be retrained or fine-tuned with new data, ensuring the knowledge extraction process remains current and relevant.
- Reduced Bias and Human Error: While LMs aren’t entirely free from bias (they can inherit biases from training data), they do offer a level of consistency in extraction that eliminates the variability and errors that human annotators might introduce.
- Real-time Processing: LMs enable real-time knowledge extraction, particularly vital in time-sensitive areas like financial news analysis, crisis response, or live social media monitoring.
- Enhanced Search and Query Capabilities: Extracted knowledge can power semantic search engines or question-answering systems. LMs can understand user queries in natural language and provide precise answers from the extracted knowledge base.
- Integration with Other Technologies: LMs can be combined with other technologies, like knowledge graphs, to provide a visual and interconnected representation of extracted knowledge. This makes complex data more accessible and comprehensible to end-users.
- Cost Efficiency: Automating the knowledge extraction process with LMs can lead to significant cost savings in the long run, especially when considering the human resources that would otherwise be required for manual extraction.
Language models play a pivotal role in transforming the sea of unstructured data into actionable, structured insights. Their capability to understand, adapt, and scale positions them as invaluable tools in knowledge extraction, powering a myriad of applications that drive our information-driven society.
Comparison of Top Models
Meta Llama 2
Llama 2 is an open-source collection of pre-trained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. The Llama 2 collection scores high for safety; in practice, this is detrimental as it will refuse to summarize data about specific people or events. Starting at 7B parameters, it can also be expensive to run.
AWS Titan Text on AWS Bedrock is a generative large language model (LLM) for tasks such as summarization, text generation (for example, creating a blog post), classification, open-ended Q&A, and information extraction.
ChatGPT-4 (OpenAI)
ChatGPT, which stands for Chat Generative Pre-trained Transformer, is a large language model-based chatbot developed by OpenAI. ChatGPT is closed-source, so it can’t be run locally. The service’s limited context windows and rate limits will slow you down unless you set up a paid subscription.
Falcon 40B
Falcon-40B is a 40B (billion) parameters causal decoder-only model built by TII and trained on 1,000B tokens of RefinedWeb enhanced with curated corpora. You will need at least 85–100GB of memory to run inference with Falcon-40B swiftly.
Storage Platforms for Knowledge Graphs
A Preface
In the domain of knowledge representation, the choice of storage platform can dramatically influence the efficiency, scalability, and accessibility of the knowledge graph. Different platforms cater to different needs, and choosing the right one often requires a balance between ease of use, flexibility, performance, and scalability. In this section, we will delve into two distinct storage options that have gained prominence in the realm of knowledge graph storage: Neo4j, a dedicated graph database designed for intricate graph operations, and JSON, a lightweight and widely-used data-interchange format adaptable for hierarchical data structures. Both options offer unique advantages and considerations, and our objective is to provide a clear understanding to help inform your choice.
1. Neo4j is a highly popular graph database designed to efficiently store, query, and manage graph-structured data. Unlike traditional relational databases based on tables, Neo4j uses nodes and relationships, making it particularly well-suited for knowledge graph applications.
- Nodes: Represent entities in the graph, such as people, products, or concepts.
- Relationships: Connect nodes and carry a type, direction, and potential properties.
- Cypher Query Language: A powerful and expressive language designed for querying graph data in Neo4j. It allows users to retrieve and manipulate data efficiently.
- ACID Compliance: Guarantees data reliability even during failures, ensuring that all database transactions are accurate, consistent, and traceable.
Benefits of Using a Dedicated Graph Database
- Performance: Neo4j is optimized for graph processing, offering speedy traversals even for complex queries involving multiple nodes and relationships.
- Flexibility: Graph databases like Neo4j can handle evolving schemas. As the structure of your knowledge grows or changes, Neo4j can adapt without requiring major database redesigns.
- Intuitive Representation: Graphs are a natural way to represent interconnected data, making them intuitive for developers and end-users to understand and interact with.
- Advanced Analytics: With built-in graph algorithms, Neo4j supports advanced analytics tasks, including recommendation systems, fraud detection, and more.
Considerations and Challenges
Running Neo4j locally requires adequate hardware, especially for larger graphs. RAM, in particular, can be a limiting factor as Neo4j benefits from caching as much of the graph as possible. While Neo4j can handle large graphs, there might be a need for clustering and sharding to maintain performance as your knowledge graph grows.
JSON (JavaScript Object Notation) or JSON is a lightweight data-interchange format that is easy for humans to read and write and easy for machines to parse and generate. While not specifically designed for graphs, it can represent hierarchical or graph-like data structures.
- Tree-like Structure: JSON naturally represents hierarchical structures with nested objects and arrays, which can be adapted to depict certain graphs.
- Wide Acceptance: JSON is language-agnostic, with parsers in almost every programming language.
- Human-readable: Being textual and minimally verbose, JSON is easily editable and understandable by developers.
2. Using JSON for Knowledge Graphs
- Nodes and Edges: Entities (nodes) can be represented as objects with unique IDs, attributes, and lists of relationships. Relationships (edges) can be depicted as arrays or nested objects pointing to other entities.
- Graph Traversal: While JSON can represent graph-like structures, traversing the graph (especially for complex queries) can be more cumbersome than dedicated graph databases. Custom code or additional tools might be needed.
- Standardization: Adopting a consistent schema or structure for representing the graph in JSON is crucial. This ensures clarity and aids in parsing and updating the graph.
Benefits
- Portability: JSON files can be easily shared, stored, or even version-controlled using platforms like GitHub.
- Integration with Web Technologies: Given its origins in JavaScript, JSON is seamlessly integrated into web ecosystems, making it ideal for web-based knowledge graph visualizations or applications.
- Lightweight: JSON can offer a simpler, less resource-intensive solution for smaller knowledge graphs or projects than setting up a dedicated graph database.
Considerations and Limitations
- Scalability: As the size of the knowledge graph grows, managing it in JSON can become challenging. Performance issues can arise when parsing or updating large JSON files.
- Lack of Query Language: Unlike graph databases with dedicated query languages, JSON requires custom functions or methods to query or update the graph.
- No Built-in Analytics: As provided by graph databases, advanced graph analytics are not natively available with JSON. Any graph algorithms or analyses would need to be custom-coded.
- Data Integrity: Without the strict transactional consistency of databases, care must be taken to ensure the integrity and consistency of the graph data in JSON.
Practical Example: Knowledge Graph from Wikipedia Text
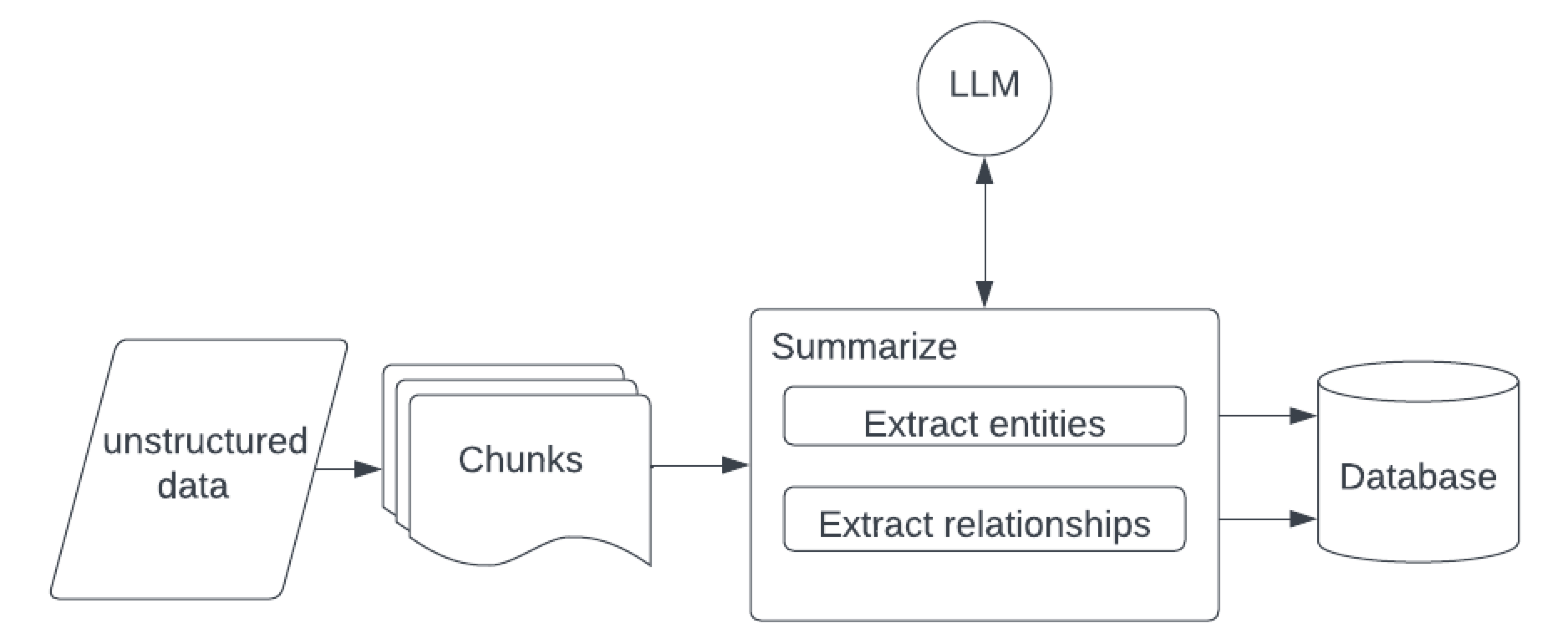
Approach
- Parse the unstructured text into chunks
- Provide the chunks with a summarization prompt
- Extract the entities and relationships from the summarized text
- Write the entities and relationships to the database
- Provide the DB schema and prompt for a query to answer the given question
- Run the LLM-crafted query
- Prompt for a well-formatted answer given the query result
Source Text (sample)
Galileo studied speed and velocity, gravity and free fall, the principle of relativity, inertia, and projectile motion and also worked in applied science and technology, describing the properties of pendulums and “hydrostatic balances”. He invented the thermoscope and various military compasses and used the telescope for scientific observations of celestial objects. His contributions to observational astronomy include telescopic confirmation of the phases of Venus, observation of the four largest satellites of Jupiter, observation of Saturn’s rings, and analysis of lunar craters and sunspots.
Resulting Graph
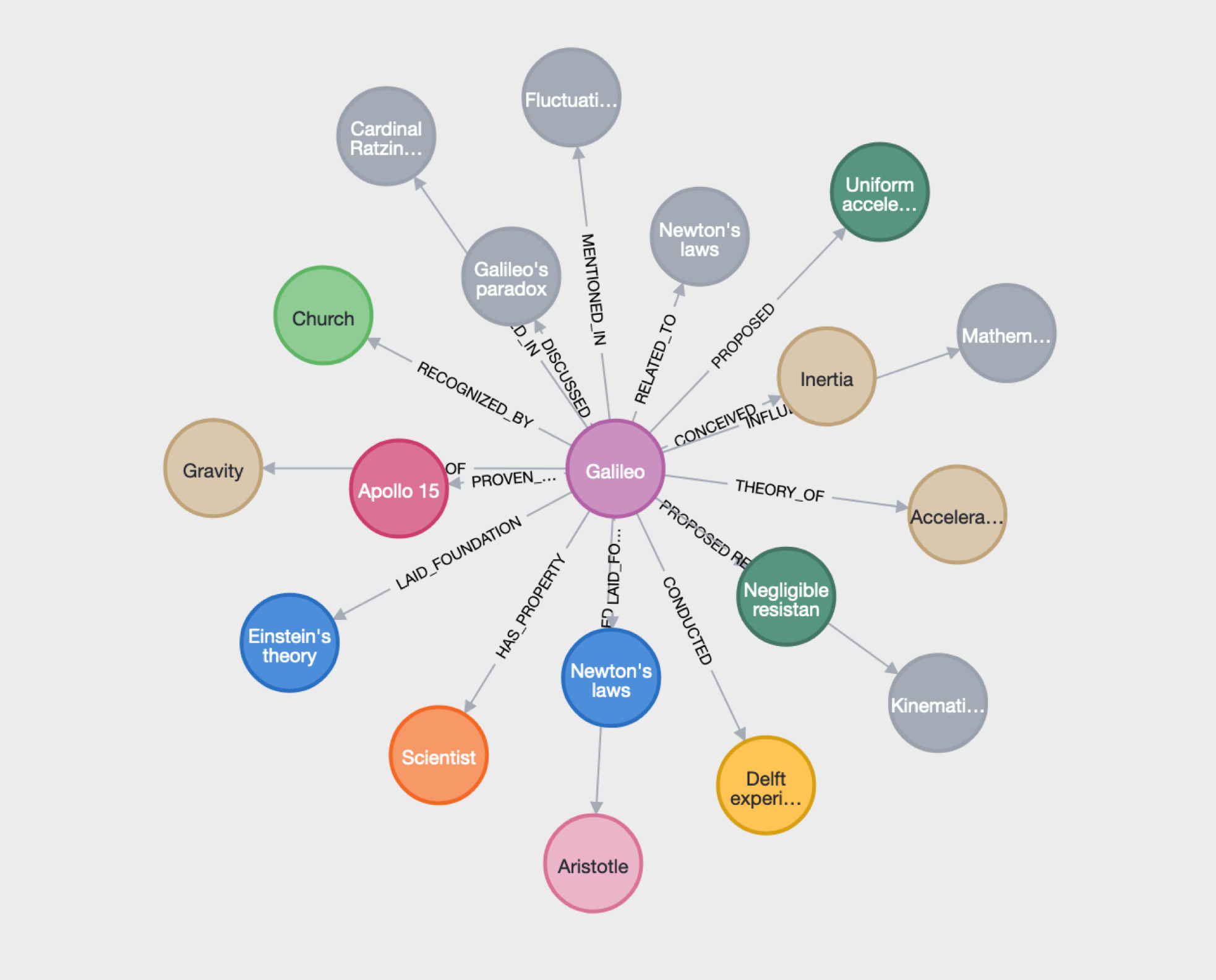
As you can see, the LLM successfully crafted cypher commands that summarized both the entities and relationships contained in the unstructured text. The resulting graph can then be consumed by a multitude of client applications, including LLM-powered applications.
Best Practices and Tips for Using Large Language Models in Knowledge Graph Creation
Define Clear Objectives
- Before delving into knowledge graph creation, clearly understand the end goal. Is it for data visualization, recommendation systems, semantic search, or another purpose?
- Tailor your approach based on your objectives, as this will impact decisions such as which data sources to include, which model to use, and how to structure your graph.
Data Quality and Pre-processing
- Ensure that the data feeding into the language model is of high quality. Garbage in equals garbage out.
- Use data cleaning techniques, remove duplicates, correct any apparent misinformation, and preprocess the data into a suitable format for the model.
Regular Updates
- Knowledge isn’t static. Regularly update your knowledge graph by re-running the language model on new data or integrating updates from reliable sources.
- Schedule periodic validations to ensure the currentness and accuracy of the knowledge graph.
Conclusion
Our expertise has been enriched through successfully implementing Knowledge Graphs (KGs) and Large Language Models (LLMs) to address complex challenges across various sectors. From enhancing customer experiences to unveiling hidden patterns in vast datasets, our solutions have consistently delivered transformative results. Recognizing the potential and intricacies of LLMs and KGs, we are poised to assist businesses in leveraging these powerful tools. If you’re curious about unlocking new opportunities and insights for your business using LLMs and KGs, we invite you to start a conversation with us. Reach out to us at NewMathData.com, and let’s explore the future together.