







Use AWS Bedrock language models with a Slack-powered chatbot
co-authors: Meghana Venkataswamy, Sean Cahill, Salman Ahmed Mian

- Architecture
- What is a Foundational Model?
- How Do we customize the FM to our Data and needs?
- Our /hr-bot uses RAG Technique
- FAISS (Facebook AI Similarity Search)
- What is AWS Kendra
- LangChain
- AWS Bedrock
- Slack integration
- Terraform
- Challenges and opportunities
Navigating policy and rules in a large or growing organization is difficult. Even if you know where all company policies live, knowing how they apply in various situations or geographies can be challenging.
You could ping your HR representative, who is more than happy to help you, but what if you ask a chatbot versed in your company’s specific guidelines?
Enter /hr-bot, the LLM-powered Slack chatbot steeped in your company’s internal documentation! Now, you can ask any question (or the same questions!) and get answers instantly and without diverting resources away from critical administrative tasks! From “What is the company policy on eating tuna at my desk?” to “Explain New Math Data’s culture to me in the style of Shakespeare,” all your burning questions answered w/ zero shame!
This POC uses a server-less AWS Bedrock endpoint, a Lambda function, and a custom Slack app and can use Retrieval Augmented Generation from your own internal documentation to provide a Q&A functionality personalized with your own documentation.
Architecture
Leveraging the AWS ecosystem and the latest language models, we created a Slack bot that uses text embeddings and the Claude LLM to provide responsive, real-time inference to complete responses to HR and company policy-related questions. The application is completely serverless and is deployed through Terraform IAC. We developed a vector store database using FAISS containing the complete corpus of HR policy documents from Confluence and then used LangChain inside a Lambda function to embed the vectorized tokens and send the prompt to the LLM. The response is parsed and sent back to the Slack webhook.
What is a Foundational Model?
Any model trained on a broad set of data (usually self-supervised at scale) that can be adapted/fine-tuned to various downstream tasks. Tasks like Generating Texts, Images, Speech, Code, etc. AWS Bedrock provides 4 Foundational Models:
- Anthropic Claude – LLM (multilingual, 12k max tokens)
- AWS Titan – LLM (English, 8k max tokens)
- AI21 Jurassic – LLM (multilingual, 8191 max tokens)
- Stable Diffusion – Text-To-Image (8192 max tokens)
How Do we customize the FM to our Data and needs?
- Fine-Tuning:
Providing additional training to model on specialized datasets.
It can be thought of as Continuing Education for a foundational model.
It’s much cheaper compared to training one from scratch.
Updates Weights of the Original Model, in effect, giving you a new model. - Retrieval Augmented Generation: Provide additional context at prompt time. “Retrieving” refers to selecting relevant documents from the data store based on the input sequence (prompt). The retrieved documents are then fed to the model along with the prompt to generate a response.
Our /hr-bot uses RAG Technique
RAG allows for external data (usually a dense vector index) that can provide the necessary context an LLM needs to answer a prompt accurately.
Pros:
- We can easily swap out retrieval algorithms and data stores (our “/hr-bot” can use two!)
- Can provide very accurate responses contingent upon the quality of the retrieved documents
- Can swap out models as well
Cons:
- Prompts include the additional context, which increases tokens in request – LLMs usually bill per token
- Services such as AWS Kendra have an hourly cost of over $1, which can add up quickly
Now that we have data and want to retrieve it to augment our model, how do we do it?
FAISS (Facebook AI Similarity Search)
FAISS is a library – developed by Facebook AI – that enables efficient similarity search. So, given a set of vectors (embeddings), we can index them using FAISS – then, using another vector (the query vector), we search for the most similar vectors within the index (Vector Store). Vector Stores stores and queries unstructured data as vectors. FAISS is widely used for high-dimensional data similarity search and clustering. It benefits large-scale machine learning tasks, including nearest neighbor search, clustering, and approximate nearest neighbor search. Pinecone is a popular Vector Database that uses FAISS.
First Iteration:
- During our Lambda function deployment, we initialized the FAISS Vector Store In-Memory
- We fed FAISS with Embeddings of a Knowledge Corpus from an existing Large Language Model (Titan) using Bedrock
- Then, we gave it our list of documents (confluence docs from s3) to generate our own data’s embeddings as well
Next Iteration:
- Second Iteration:
We used AWS Kendra as our document “Retriever”
What is AWS Kendra?
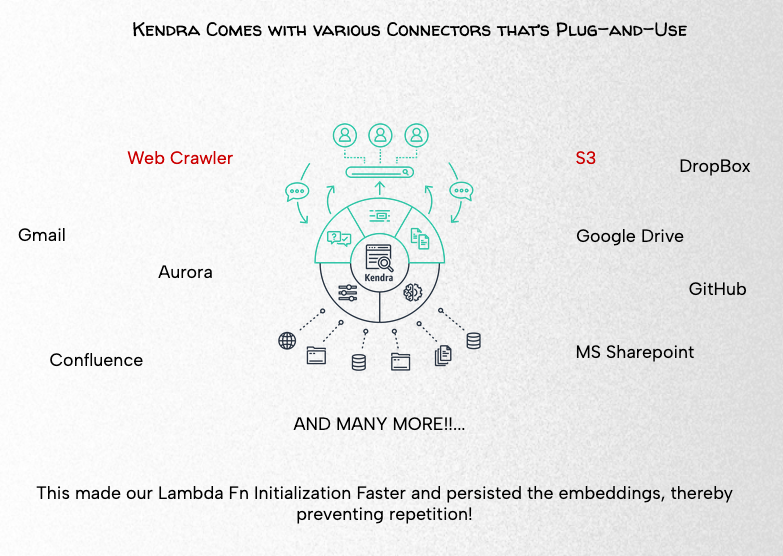
Amazon Kendra is a fully managed service that provides out-of-the-box semantic search capabilities. Meaning: no need to deal with word embeddings, document chunking, and other lower-level complexities
Amazon Kendra offers easy-to-use deep learning search models that are pre-trained on 14 domains and don’t require any ML expertise.
LangChain
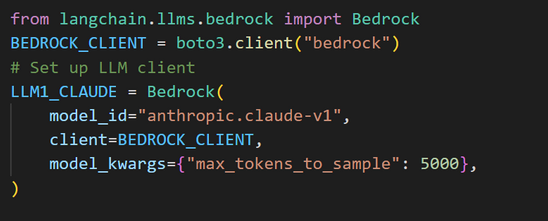
AWS Bedrock
Bedrock is a fully managed service providing access to Foundational Models (from Amazon and other leading AI providers) via an API. With the serverless experience, we can quickly start and easily experiment with FMs. We can privately customize FMs with our own data and seamlessly integrate and deploy them into our applications.
Less Work than hosting our own FMs securely on the cloud!
Slack integration
Developed and tested the app locally with Slack CLI. Slack CLI generates app scaffolding and triggers for you using commands, making it easy to get going. They are coded in TypeScript, so brush up if you’re not a front-end dev! There are also Slack CLI commands to deploy the app.
Terraform
Infrastructure as Code (IAC) built with Terraform enables rapid deployment of parameterized environments using a DRY (don’t repeat yourself) methodology.
Challenges and opportunities
As this was a POC, we left some work on the table for future efforts. We also documented several limitations.
- Bedrock is in limited preview; Edit: Bedrock is now GA; installing relevant packages(boto3 w/ bedrock) was tricky
- The trade-off between Speed, Accuracy, and Cost (Kendra vs. FAISS)
FAISS needs to be re-run for changes made to Data. No automation yet! - Kendra index needs to be fine-tuned
- Try out other Vector Stores
- Data and Prompts can be fine-tuned further, index columns or add some metadata
- Integrate “Memory” into the workflow to store chat history and maintain the context of the conversation
- Allow for streaming of response data back to the user instead of waiting for the entire response
- Give Other LLMs a try! Perhaps chain it with other models to generate Images, Sounds, etc..