







Introduction to Project Planning in Cloud Data Engineering Project planning is a critical component of successful data engineering projects, especially when these projects are executed in the cloud. The unique characteristics of cloud computing, such as scalability, on-demand resources, and geographic distribution, offer both opportunities and challenges that must be carefully managed through effective planning. […]

The Imperative of a Data-Driven Culture in Modern Organizations In today’s rapidly evolving business landscape, the imperative of fostering a data-driven culture within organizations cannot be overstated. As markets become increasingly competitive and the volume of data available for business operations expands, the ability to effectively harness and utilize this data stands as a critical […]
The field of Natural Language Processing (NLP) has exploded in popularity in recent years. Largely because accessibility has become so simple for the public. These days developers have such simple access to large language models (LLMs) through tools like AWS Bedrock that creating a generative AI application has never been easier. With these models […]
Exploring the Path to Leadership in the Evolving Field of Cloud Data Engineering Introduction The field of cloud data engineering is rapidly evolving, driven by the relentless pace of technological advancements and the increasing reliance on data-driven decision-making. As organizations continue to migrate their operations and data storage to cloud platforms, the demand for skilled […]
Exploring the integration of generative AI in data engineering and its ethical implications. Introduction The integration of generative AI into data engineering marks a significant evolution in the way data ecosystems are managed and utilized. As these advanced technologies take on more complex tasks traditionally performed by humans, they bring forth not only enhanced efficiency […]

Introduction to Generative AI and Its Impact Across Different Industries Generative AI is revolutionizing industries by automating creative processes and enhancing decision-making capabilities. This technology uses algorithms to generate content, solve problems, and derive insights from vast datasets, becoming a crucial tool across various sectors. As industries aim to harness the power of generative AI, […]
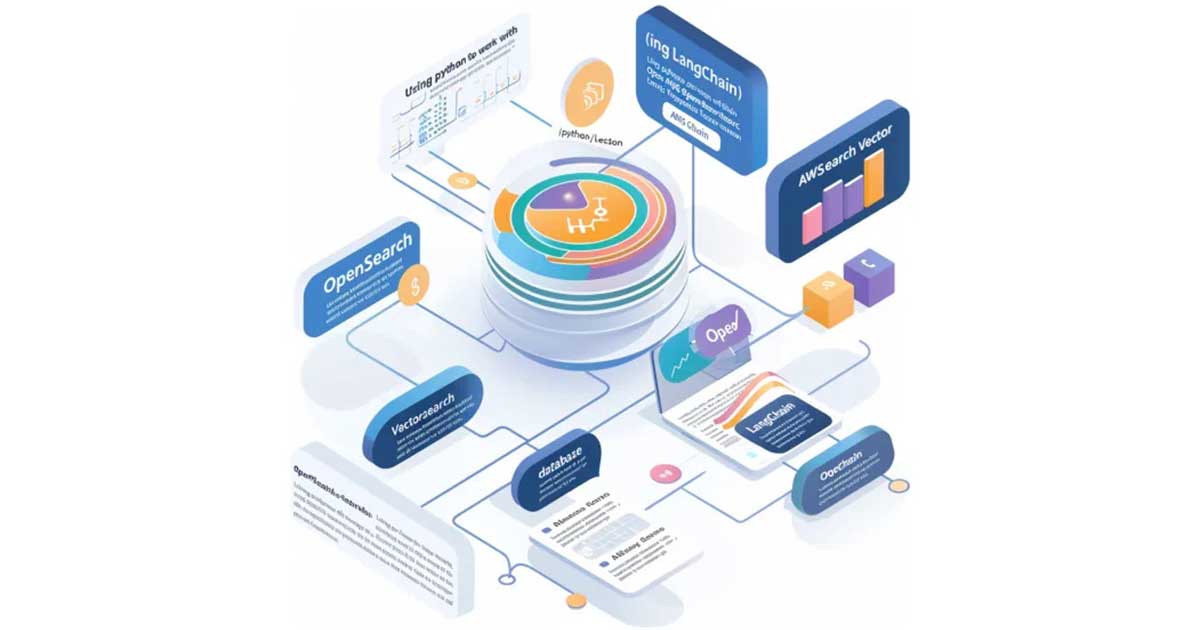
Introduction In this blog post we will introduce vector databases and some of the algorithms used for indexing and show examples of how to work with AWS OpenSearch vector database using python and LangChain library. Vector databases A vector database is a type of database that stores high-dimensional vectors for fast retrieval and similarity search. […]

Introduction HireBot is a chatbot designed to streamline the initial screening process of candidate resumes and profiles for recruiters and hiring managers. It leverages natural language processing to interpret resumes, allowing users to query candidate information through a natural language interface. The primary issue HireBot addresses is the time-consuming nature of manual resume screening, reducing […]

First things first, what is data quality monitoring? Data quality monitoring for machine learning can generally be thought of from two perspectives. One perspective is that of traditional data-engineering. This type of monitoring is concerned with the “physical” characteristics of the data and ensuring they are what you expect them to be. It involves criteria […]
Introduction Data pipelines in AWS orchestrate the movement and transformation of data across various AWS services. The core objective of these pipelines is to enable efficient data processing, analysis, and storage, ensuring that data is available where and when it is needed. Maintaining high data quality throughout this process is critical; it ensures reliability, accuracy, […]